
PDF 取证案例研究:Epstein 文件集 PDF
在“Epstein 文件透明法案”下,美国司法部公开了一批 PDF 文档,引发了公众对涂黑与清理(sanitization)是否到位的技术讨论。本文以 PDF 协会的技术通报为依据,从纯数字取证视角梳理这些 PDF 的结构特征与常见误解,重点关注文件语法、增量更新、Bates 编号与元数据,而非内容本身或法律解读。
范围与说明:本文整合参考分析与通用 PDF 诊断实践;并非逐份文件详查,不代表对特定产品的背书,亦不构成法律建议。

- 2025 年 12 月 26 日更新
- 样本与观察范围
- 文件有效性
- PDF 版本
- 增量更新
- Bates 编号
- 第一次增量更新
- 不同的增量更新
- 元数据
- 照片类内容
- “扫描件”还是“拼合页”?
- 常见问答
- 结语
2025 年 12 月 26 日更新
司法部随后发布 DataSet 8.zip(压缩后 9.95 GB),包含 10,593 份新 PDF(约 1.8 GB、29,343 页;最长 1,060 页)以及大量 MP4、表格与其他文件。首尾 PDF 被报告为:
- VOL00008\IMAGES\0001\EFTA00009676.pdf
- VOL00008\IMAGES\0011\EFTA00039023.pdf
粗略查看显示其 pdfinfo 属性与早前数据集相似;未见更深入分析的公开结论。
针对网络上“可恢复涂黑”的传言,参考分析明确指出:对数据集 01–07 的 EFTA PDFs 而言,涂黑处理是正确的,不存在可恢复的被遮蔽文本。媒体示例(VOL00004\IMAGES\0001\EFTA00005855.pdf)被点名为完全、正确涂黑。可提取文本如有,通常仅为低质量 OCR 的乱码与 Bates 编号,这是预期现象。
样本与观察范围
本文聚焦 EFTA 披露中随机抽取的 PDF 子集,重点检视:
- 文件语法与结构(对象、xref/索引、trailer、EOF)
- 增量更新及其意图(加盖、涂黑、OCR、组装)
- 元数据/XMP、嵌入资源与显隐内容
- 诉讼与信息公开常见工作流特征(Bates、.OPT 载入文件)
不评述文档叙事内容,亦避免针对特定工具的主观判断。
文件有效性
合规 PDF 满足 ISO 32000 的头部、交叉引用、trailer 与 EOF 等要求。常用核验:
- 使用
pdfinfo查看版本、页数、页面尺寸 - 使用
qpdf --check或qpdf --validate=pdf20识别结构问题 - 经验性检查:单一 %%EOF、xref 一致、对象计数匹配
注意:下述现象并非恶意的直接证据——
- 生产者(Producer)字段的工具差异或怪癖
- 旧线性化(linearization)残留
- 对象排序或 trailer 细微异常
PDF 版本
同一语料中出现多个版本很常见,原因往往是工具链与历史处理步骤混杂:
- 旧的 1.x 与较新的 2.0 样式并存
- 后期版本更可能启用对象流、压缩 xref
- 某些功能(如透明度、XMP)会触发版本提升
取证启示:版本差异本身并不反常,更多反映了“不同工具、不同阶段”的正常处理轨迹。
增量更新
增量更新通过在文件尾部追加新对象与 xref 来保留历史内容。常见于:
- Bates 编号盖章、页面标签更新
- 涂黑流程(尤其后续的“烧录/合并”)
- OCR 增补隐藏或标注文本层
识别要点:
- 多个 %%EOF 与追加的 xref 区段
- trailer 指示前一修订版本
- 页面外观改变但文件非全量重写
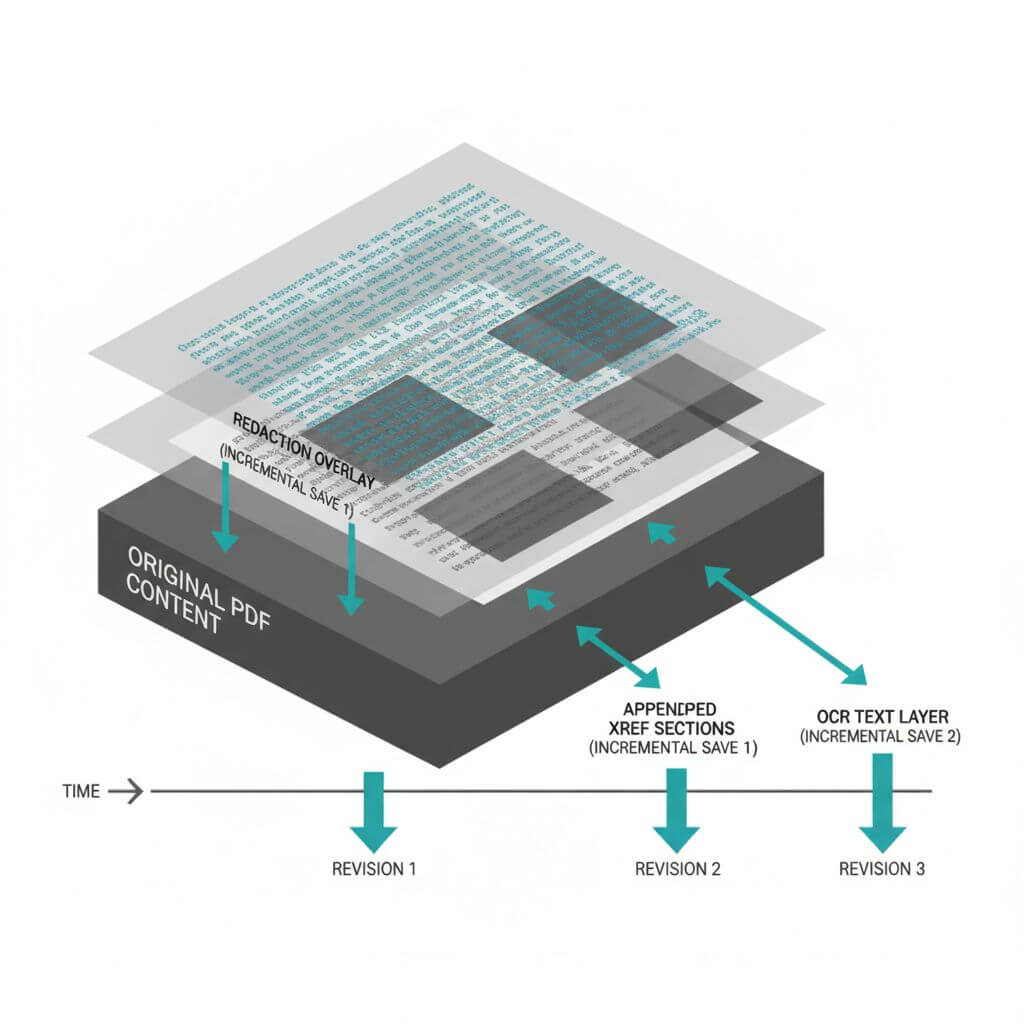
增量更新应核验什么?
- 涂黑是向上遮挡(overlay)还是已彻底“烧录/移除”?
- 是否残留隐藏图层或注释?
- 更新顺序是否符合预期(如 盖章→涂黑→OCR)?
Bates 编号
Bates 是诉讼中用于标识页面的编号。在 EFTA 数据中,Bates 编号与“.OPT”载入文件的关系,符合常见的电子取证与交付实践。
建议核验:
- 每页是否存在可见的 Bates 印记
- 文本提取能否在预期处得到 Bates
- 文件名、页码范围能否与 .OPT 载入文件相互印证
实用技巧:在大语料中,先在 .OPT 中检索 Bates 范围,可快速定位目标文档。
第一次增量更新
首个追加修订往往对应早期编目/组装节点:
- 统一页面尺寸与旋转
- 批量加盖 Bates
- 初次 OCR 以便检索
如何检查:
- 比较第一次更新前后的对象数量与 xref 改动
- 查找与印章相关的新 Form XObject 或注释字典
- 关注 Producer/Creator 的变化以定位流程节点
不同的增量更新
后续修订通常反映:
- 涂黑(并“烧录”)与可视遮罩
- OCR 的补救或语言包加持
- 页面替换(如更清晰的扫描)或附件追加
区分更新意图:
- 涂黑工具可能引入特定命名模式的对象
- OCR 往往新增带标记内容的流(marked-content)
- 替换页会体现为新的 XObject 或页面字典
元数据
元数据既来自 Info 字典,也来自 XMP。常见现象包括:
- 不同工具与时间点导致 Producer/Creator 差异
- 作者/标题杂糅或缺失,法律工作流中往往被中性化
- 源图像嵌入 PDF 后,原始 EXIF 常被剥离
核验路径:
exiftool -XMP:all -s -G file.pdf查看 XMP- 比对 Info 与 XMP,二者不一致未必异常
- 从 Producer/Creator 中识别涂黑/清理工具痕迹
照片类内容
若 PDF 含照片:
- 通常二次压缩并剥离原始 EXIF
- 可能有降采样与色彩配置(ICC)转换
- 取证线索包括 JPEG 分块边界、ICC 配置、图像 XObject 复用
解读注意:二次压缩为诉讼/交付常态;PDF 内缺失相机 EXIF 并不等于可疑改动。
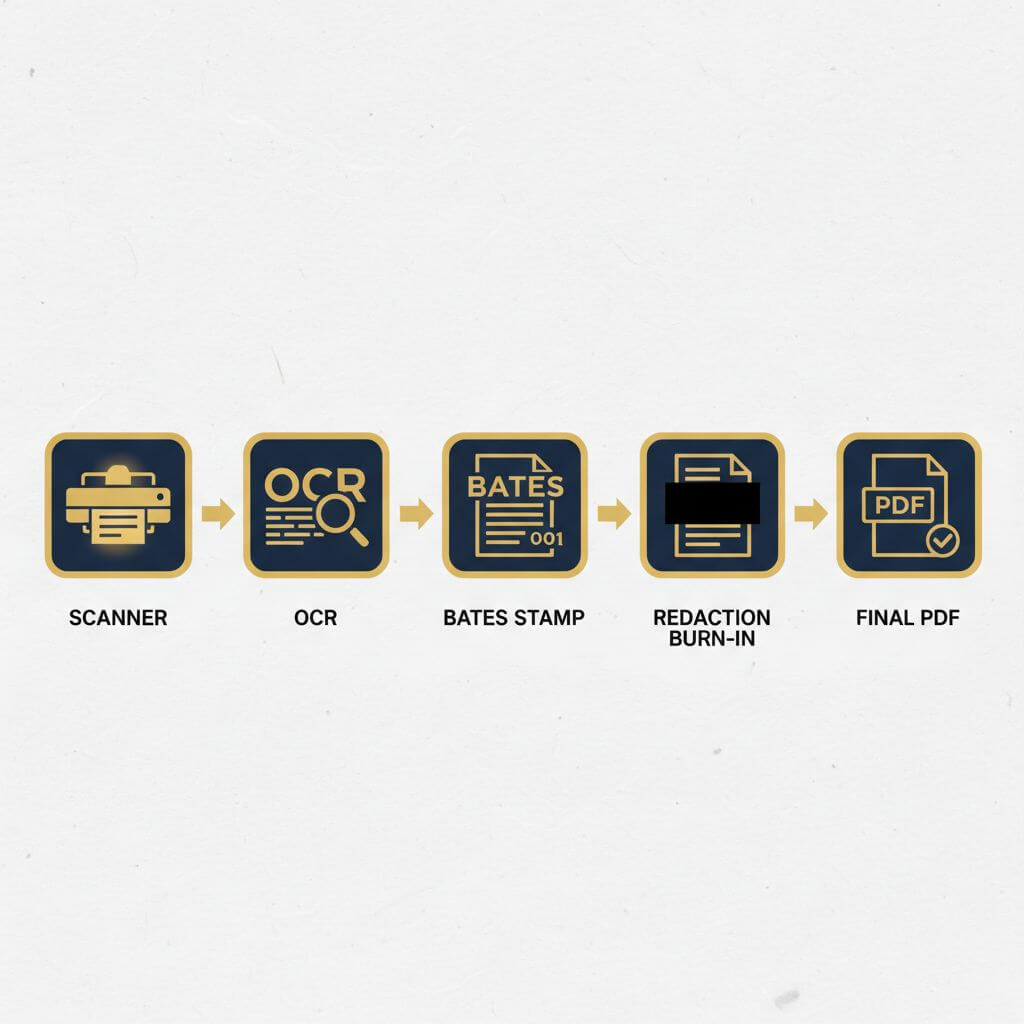
“扫描件”还是“拼合页”?
看似纯扫描的页面,仍可能包含分层工件:
- 为提升检索性而叠加的 OCR 文本(有时乱码)
- 涂黑矩形先为矢量/注释,随后再“烧录”
- 页面裁切/旋转与纸张尺寸不完全一致
判别方法:
- 尝试文本选择与提取(
pdftotext或编辑器全选)并观察输出 - 检查内容流是纯图像页,抑或图像+矢量/文本混合
- 确认涂黑不是“注释”而是真正的删除/合并
常见问答
EFTA PDFs 的涂黑可恢复吗?
据参考分析,对于数据集 01–07 的 EFTA PDFs,涂黑是正确、不可恢复的。可提取内容(如有)多为低质量 OCR 乱码与 Bates 编号,属预期现象。
为何恶意软件分析网站偶尔会“误报”?
启发式检测可能将无害特性(如 JavaScript 条目、嵌入对象、异常对象图)误判为风险。结构异常或增量更新本身并不等同于恶意或隐藏文本。
实务中应做哪些快速检查?
- 以
pdfinfo确认版本与页数 - 以
qpdf --check验证结构 - 尝试文本提取,了解可选择文本范围
- 对可疑涂黑进行对象层级与十六进制视图抽查
.OPT 文件有何用途?
.OPT 载入文件将 Bates 与图像/PDF 页做映射。在大规模语料中检索 .OPT,可高效定位目标文档与核验页码范围。
结语
从 PDF 取证视角看,EFTA 语料体现了典型的诉讼生产特征:一致的 Bates 编号、与加盖/OCR/涂黑相匹配的增量更新、多样化的 PDF 版本与因工具链差异导致的元数据变化。针对“可恢复涂黑”的高关注度传言,参考分析已对 EFTA 数据集 01–07 予以澄清:不成立。实践中仍应持续验证涂黑工作流、确认“烧录”已执行,并记录各修订步骤以保证可追溯性。
研究过程中如需将网页快速转为 PDF 或 Markdown,亦可试试 URL to Any (https://urltoany.com)。