
Firecrawl 替代方案:单页 URL 转 Markdown 何时就够
今天早上 Prometheus by Firecrawl 冲上 Product Hunt 第 3 名——一个"面向 web data 的前置部署 agent"(forward deployed agent)。于是各个 AI 团队的群里都在问同一个问题:要不要把数据管线重建在它之上?但在把一个爬取 agent 接进技术栈之前,先问一个更省钱的问题:眼下这个任务,你真的需要"爬"吗?
很多所谓的 "web data" 任务根本不是爬取。URL 你已经有了,你需要的只是把这一个页面转成干净的 Markdown 喂给 LLM、转成 JSON 填进表格,或者存成研究笔记。这正是一款面向单页提取的 Firecrawl 替代方案大显身手的地方——大约两秒搞定,不需要 API key,不需要 schema,也不需要 agent 循环。本文要划清这条线:什么时候完整的爬取/agent 管线值这个成本,什么时候简单的 URL 转 Markdown 提取就够了。
最后更新:2026-06-14。
目录
- 什么是 Firecrawl?什么是 web data agent?
- 爬取 agent vs 单页提取:边界在哪里
- 主流 Firecrawl 替代方案对比
- 功能对比表
- 如何选择合适的 Firecrawl 替代方案
- 不用爬虫,如何把 URL 转成 Markdown 或 JSON
- 常见问题
什么是 Firecrawl?什么是 web data agent?
Firecrawl 是一个把网站转成 LLM 可读数据的 API:可以抓单页、爬整站、列出所有 URL,或用 schema 提取结构化字段。它新推出的前置部署 agent——Prometheus——能自主规划并执行这些步骤。两者都处在 web data 的"管线"一端;单页转换工具则在另一端。
实际上,Firecrawl 提供一组任务:
- Scrape——抓取单个页面,返回干净的 Markdown、HTML 或结构化数据。
- Crawl——沿链接爬遍整个域名,返回每个页面。
- Map——只列出站点所有 URL,不抓正文。
- Extract——用 LLM 加 schema(或 prompt)跨多页提取结构化字段。
Firecrawl 开源、可自托管,且在最关键的地方很强:重 JavaScript 的页面、反爬防御,以及大规模多页任务。2026 年 6 月 14 日在 Product Hunt 上线的 Prometheus 更进一步——不用你逐个调用接口,而是由 agent 决定访问哪些页面、提取什么内容。对于开放式的"去全网找这份数据"任务,这确实有用。
问题在于,这一切都是一条管线。你要注册、拿 API key、学接口(或 agent 的用法),再按 credit 付费。对整站爬取或定时提取,这点开销物有所值;但对"读这一个页面"来说,杀鸡用了牛刀——而这恰恰是更轻量的 Firecrawl 替代方案的位置。
爬取 agent vs 单页提取:边界在哪里
边界很简单:如果你已经有 URL,要的是这个页面的内容,那就用单页提取;如果你需要发现页面、沿链接抓取,或在成百上千个 URL 上提取同一套 schema,那才需要爬取 agent。大多数 LLM 和研究类任务属于前者。
| 问题 | 爬取 agent(Firecrawl / Prometheus) | 单页提取 |
|---|---|---|
| 你手上有什么 | 一个种子域名或一个模糊目标 | 已经有确切的 URL |
| 你想要什么 | 跨多页发现 + 提取 | 你指定的页面的内容 |
| 输出形态 | 规模化的数据集 / 结构化记录 | 一份干净的 Markdown 或 JSON |
| 典型量级 | 几百到上百万页 | 一到几十页 |
| 配置成本 | API key、schema、credit,有时还要写 agent prompt | 粘贴 URL,或一次 API 调用 |
| 最适合 | 整站爬取、监控、schema 提取 | LLM 上下文、研究笔记、数据整理 |
一个好用的判断:如果你能把想要的 URL 一个个说出来,那基本不需要爬取;如果你只能说出站点、还得去找对的页面,那才轮到 agent 管线出场。
主流 Firecrawl 替代方案对比
最合适的 Firecrawl 替代方案取决于你的任务是"爬"还是"读单页"。下面是覆盖整个区间的五个选项——从重型爬取基础设施到免费单页转换器——并如实列出各自的强项与短板。
1. Firecrawl + Prometheus(基准)。 规模化、schema 驱动、agent 化 web data 的参照系。
- 最适合: 整站爬取、跨多页结构化提取、重 JS 与反爬站点、"全网找数据"的 agent 化任务。
- 不太适合: 一次性的单页转换、对成本敏感的零散任务、想要零配置的人。你付出的 credit 和接入时间,可能换来用不上的能力。
2. Jina Reader(r.jina.ai)。 在 URL 前加 r.jina.ai/ 就能拿到 LLM 可读的 Markdown。
- 最适合: 在脚本和 agent 里快速取单页 Markdown、免费额度慷慨、接入极简。
- 不太适合: 整站爬取、Markdown 之外的多格式、内置结构化字段提取。
3. URL to Any(urltoany.com)。 免费在线工具,把单个 URL 转成 Markdown、JSON、Text、HTML、XML、PDF、图片或 MP3,还带 AI 总结和 meta 标签提取。
- 最适合: 粘贴 URL,约两秒拿到干净的 Markdown 或 JSON,无需注册,一个页面多种输出格式,喂 LLM 或存研究笔记。
- 不太适合: 爬整站、定时监控任务,或在上千页上提取同一套 schema——它为"你已经有的页面"而生,不做整站发现。
4. 本地自建(markitdown、Trafilatura、Pandoc、readability)。 自己运行的开源库。
- 最适合: 完全可控、无单次请求费用、离线与批处理管线、隐私敏感内容。
- 不太适合: JS 渲染页面和反爬站点——你得自己加无头浏览器和代理,而这正是你原本想让 Firecrawl 替你扛的大头。
5. Apify / ScrapingBee / Bright Data。 带代理和规模能力的爬取基础设施。
- 最适合: 大规模、强对抗、高并发爬取;轮换代理;带 SLA 的企业级抓取。
- 不太适合: 简单的"URL 转 Markdown 喂 LLM"——对一次读取来说,这是过重的基础设施(和成本)。
在我们对博客文章、文档页和产品页的实测中,单页工具(Jina Reader、URL to Any)返回干净 Markdown 的速度更快、配置远更少;而一旦任务变成"这个站点的每一页",Firecrawl 和 Apify 立刻就值回票价。
功能对比表
下表把每个 Firecrawl 替代方案对应到决定选择的能力上。单页工具赢在速度和零配置;爬取平台赢在整站发现和规模。
| 工具 | 整站爬取 | 单页 → MD/JSON | Schema 提取 | JS 渲染 / 反爬 | 需 API key + 注册 | 免费额度 | 最适合 |
|---|---|---|---|---|---|---|---|
| Firecrawl + Prometheus | 支持 | 支持 | 支持 | 支持 | 必需 | 有限 credit | 整站爬取、agent 化提取 |
| Jina Reader | 不支持 | 仅 Markdown | 不支持 | 部分 | 可选 | 慷慨 | 脚本里快速取 MD |
| URL to Any | 不支持 | 支持(10+ 格式) | JSON 输出 | 支持 | 无需 | 免费免注册 | 单页、多格式 |
| 本地自建库 | 自己搭 | 支持 | 自己搭 | 自己加 | 无需 | 免费(自托管) | 离线 / 私有批处理 |
| Apify / ScrapingBee | 支持 | 支持 | 附加 | 支持 | 必需 | 试用 credit | 高并发抓取 |
产品能力会随版本变化——写稿时 Prometheus 才上线几天——所以下手前请确认当前限制。但结构性结论不变:按任务形态选,而不是按品牌选。
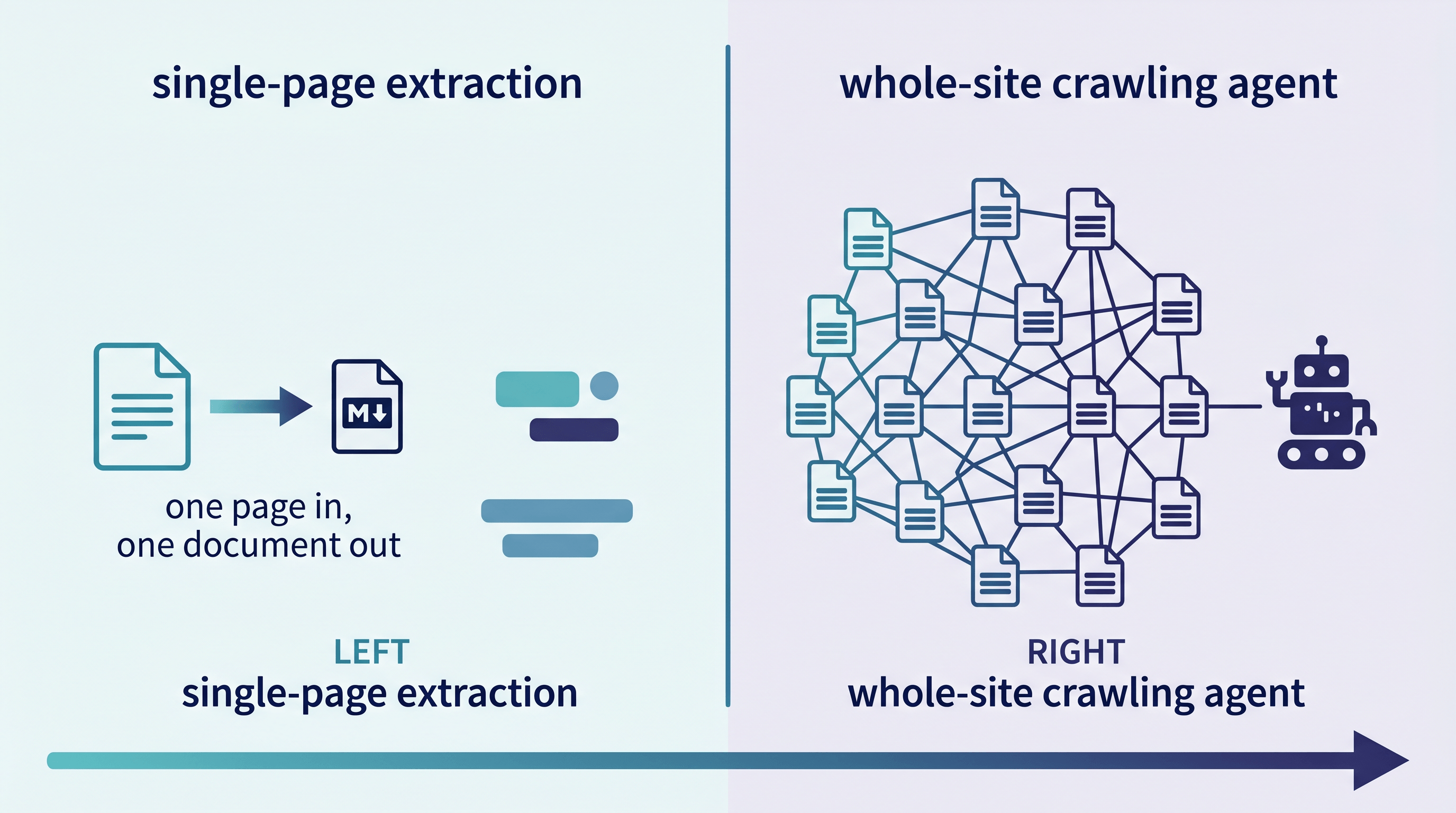
如何选择合适的 Firecrawl 替代方案
按任务形态选,而不是挑能力最强的那个。如果你能把需要的 URL 列出来,单页转换器更快也更省;如果你得发现页面或规模化提取 schema,那 Firecrawl 或 Prometheus 这类爬取 agent 才是正解。
- "我要把一个页面喂给 LLM。" 用单页转换器——URL to Markdown 或 Jina Reader,爬虫纯属多余。(关于"为什么干净 Markdown 胜过截图"的成本账,见我们的 URL to Markdown vs Computer Use 拆解。)
- "我要用十几个已知 URL 做研究简报。" 单页提取,批量处理。逐个转成 Markdown,丢进 prompt 或笔记,无需爬取。
- "我要整个文档站,或要发现所有 URL。" 这是爬取。用 Firecrawl 的
/crawl或/map,或让 Prometheus 去规划。 - "我要在上千个页面上拿同一套结构化字段。" 规模化 schema 提取——Firecrawl
/extract、Prometheus 或 Apify。 - "我对成本敏感,任务也很零散。" 免费免注册的工具胜出。等量级上来了,再升级成管线也不迟。
一个实用的做法是混合:用 Firecrawl 或 Prometheus 处理偏发现的部分,再把得到的 URL 交给快速的单页转换器去做常规读取。只在真正需要爬的地方花爬取的钱。
不用爬虫,如何把 URL 转成 Markdown 或 JSON
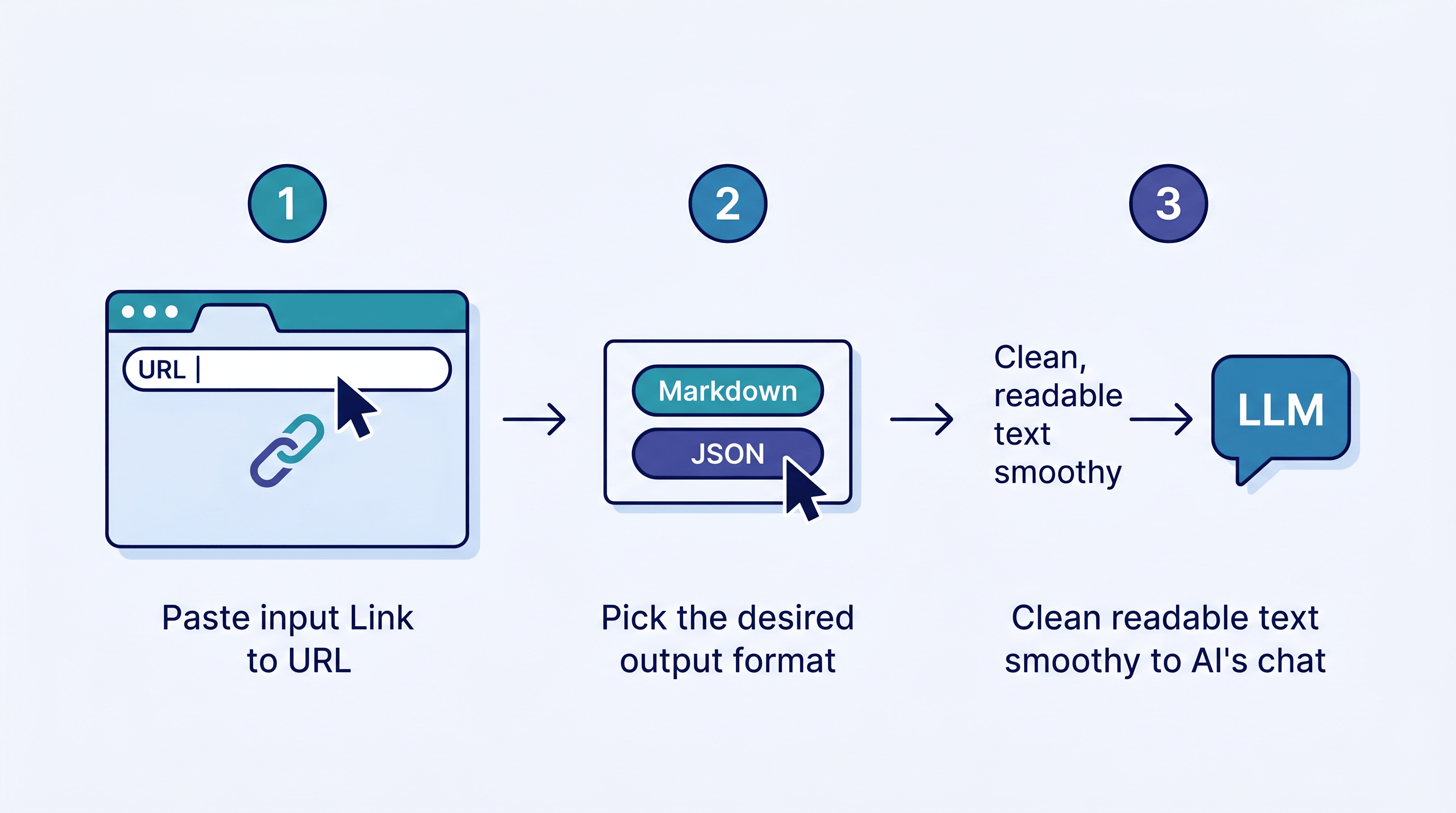
转换单个页面不需要管线。把 URL 粘进转换器,选好格式,复制结果——大约两秒就得到干净、LLM 可读的文本。下面是用 URL to Any 的最快路径。
- 复制目标页面 URL——文档页、博客文章、产品页都行。
- 打开 URL to Any,把 URL 粘进转换器。无需注册或 API key。
- 选择输出格式。 喂 LLM 和做笔记选 Markdown;需要给表格或应用的结构化字段就选 JSON。转换约两秒完成。
- 直接复制结果到你的 Claude / GPT prompt、RAG 索引或 Obsidian 库。页面很长的话,先过一遍 AI 总结 压缩 token。
- 对每个已知 URL 重复。 处理几个页面时,这比配置一次爬取更快,而且免费。
如果要接进 agent,单页思路同样适用:抓页面、转 Markdown,然后让模型读文本而不是像素。完整的 agent 接入模式见我们的 URL to Markdown 喂 LLM 指南。
常见问题
最好的免费 Firecrawl 替代方案是哪个?
就单页提取而言,最好的免费 Firecrawl 替代方案是 URL to Any(免费、免注册、含 Markdown 和 JSON 在内 10+ 输出格式)和 Jina Reader(在 URL 前加 r.jina.ai/ 即得免费 Markdown)。两者都不爬整站,但对"把这个页面转给我的 LLM"来说,几秒搞定且零配置。若要低成本做真正的整站爬取,Firecrawl 自家的免费 credit 额度或自托管开源库更对路。
只是把 URL 转成 Markdown,需要 Firecrawl 吗?
不需要。把单个 URL 转成 Markdown 是一步到位的事,免费在线工具或一次 API 调用就能瞬间完成。Firecrawl 的价值在于爬整站、规模化渲染重 JavaScript,或跨多页提取 schema。如果你已经有 URL、要的是它的内容,一款轻量的 Firecrawl 替代方案更快也更省。
Firecrawl 或 Prometheus 什么时候才真正值得用?
当任务确实是爬取或 agent 化搜索时:跨域名发现 URL、沿链接抓取、从成百上千页中提取同一套结构化字段,或应对激进的反爬防御。当目标是开放式的——"全网找这份数据"——并且你想让 agent 自己规划步骤、而非你逐个调接口时,Prometheus 才显出价值。
不用爬取 agent 能拿到结构化 JSON 吗?
能。单页转换器可以对你指定的页面返回 JSON——URL to Any 直接提供 URL to JSON 输出。只有当你想在许多不同页面上规模化地拉取同一套结构时,才需要 agent 的 schema 提取功能。
URL to Any 算 Firecrawl 的替代方案吗?
就单页提取而言,算。URL to Any 能在约两秒内把 URL 转成 Markdown、JSON、Text、PDF 等,且无需注册,覆盖了最常见的"读这个页面给 LLM 或研究用"场景。它不替代 Firecrawl 的整站爬取、定时任务或大规模 schema 提取——那些仍是管线级任务。
单页提取和网页抓取有什么区别?
单页提取读取你已有的一个页面并返回其干净正文。网页抓取(和爬取)则跨多页发现并采集数据,往往涉及沿链接、分页、代理和 schema。提取是"读",抓取是"管线"。把工具对上你真正需要的那一种,就是全部决策。
结语
当任务是真正的爬取——发现、规模、schema、对抗性站点——Prometheus 和 Firecrawl 很强。但相当一部分 "web data" 工作只是"读这个页面":把一个 URL 喂给 LLM、把文章存成 Markdown、为表格拉点 JSON。对这些场景,合适的 Firecrawl 替代方案就是一款几秒搞定、零配置的单页转换器。按任务形态选:要发现就爬,已有 URL 就转。
已经有 URL 了?跳过整条管线。免费试用 URL to Any →——约两秒把任意页面转成 Markdown、JSON、Text、PDF 等,无需注册。