AI Agent 抓网页:URL to Markdown 比 Computer Use 便宜 45 倍
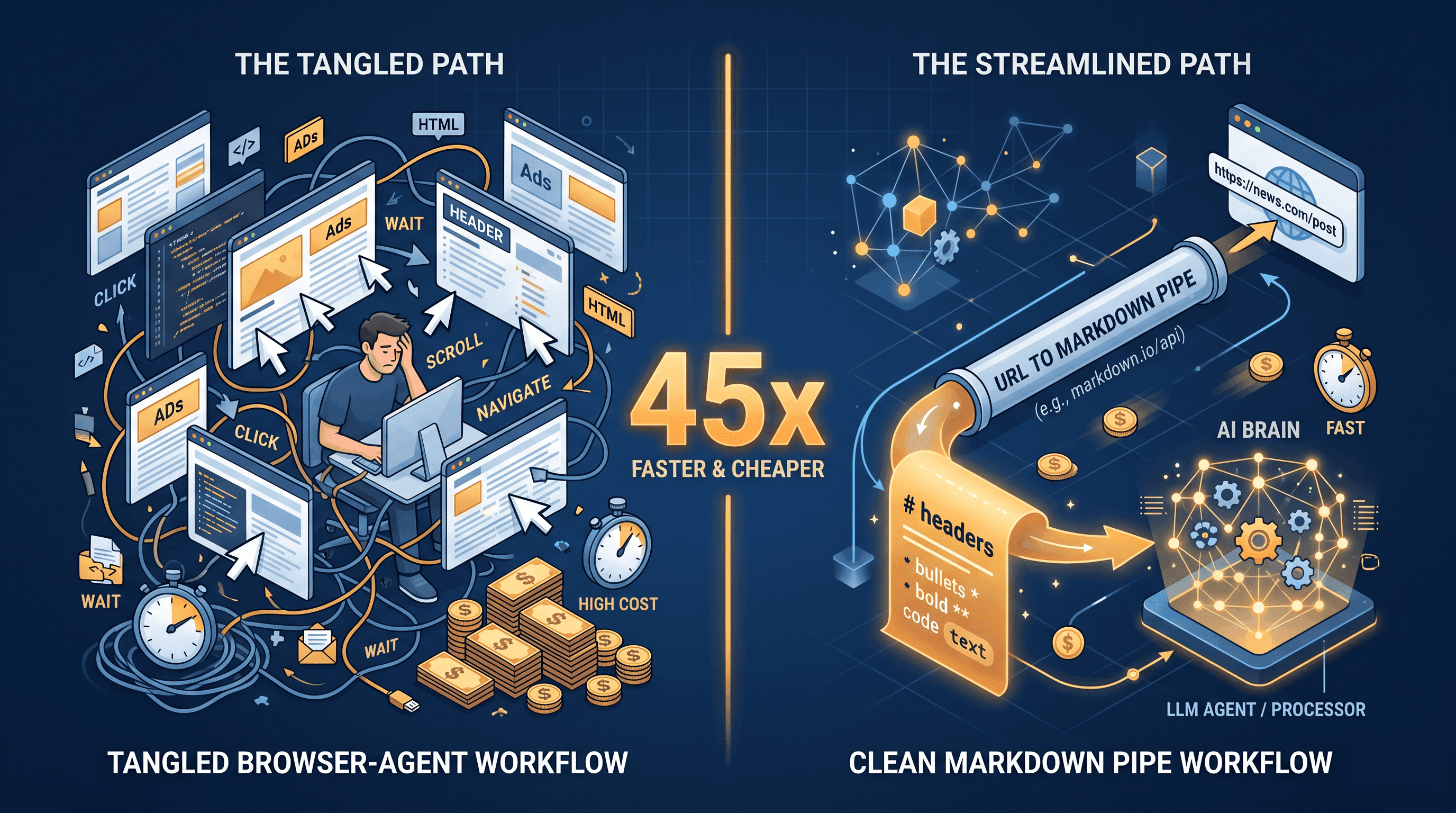
如果你在做 AI agent,今早大概率刷到了那个数字:Reflex.dev 实测 Computer Use 比直接调结构化 API 贵约 45 倍 ——让两个 agent 干同一件事:读一个网页、回答一个问题。差距来自截图、视觉 token、还有点击前后的多轮推理;而结构化 API 路径只是把 Markdown 直接塞进模型,一轮就完事。
这篇是开发者视角的翻译稿。我们对比两条路径在成本、延迟、可靠性上的差异,列出 Computer Use 仍然合理的少数场景,再用一段 30 行的 demo 展示如何把任意 URL 转成 Markdown 喂给 Claude 做问答 —— 这是当下你能给 AI agent 加的最便宜的 context 层。
最后更新:2026-05-06。
目录
- 45 倍这个数从哪来的
- Computer Use 为什么贵
- 结构化 API 路径:URL → Markdown / JSON / 摘要
- Computer Use vs 结构化 API:对比表
- 什么时候 Computer Use 仍然是对的
- 实战 demo:30 行代码把 URL 转 Markdown 喂给 AI agent
- 给 agent context 省钱的几个习惯
- FAQ
45 倍这个数从哪来的
简短版:Reflex 让两个 agent 干同一件事 —— "读一个网页、返回一个结构化结果",一个走 Computer Use,一个走 HTTP 抓取 + 结构化输出。Computer Use 那条路 token 成本约是另一条的 45 倍。差距的大头是视觉 token(Claude 的视觉计费下,一张 1280×800 截图大约值 1,000-1,500 token),加上每次点击前后的多轮推理。Reflex.dev 的原文显示这个比例在产品页、博客、搜索结果上都成立 —— 不是某个 benchmark 偶然跑出来的。
不是说"永远别用 Computer Use"。而是默认路径应该是结构化 API:URL → Markdown / JSON / 摘要 → 模型。Computer Use 是没有别的入口时的兜底。
Computer Use 为什么贵
Computer Use 把 agent 变成了"用眼睛操作的人类"。每一步大致是:
- 一张或多张截图。 1280×800 在 Claude 视觉计费下约 1,000-1,500 token。
- 一轮规划:决定点哪里。一轮动作:发出 tool call。
- 再一张截图:确认刚才点击的结果。
一个"滚动 → 关 cookie 弹窗 → 滚动 → 找到价格"的循环常见跑 6-10 轮才出答案。每轮 1k+ 视觉 token + 推理文本,单页输入 token 顺利时 10-20k,遇到弹窗、无限滚动、反爬就再翻 3-5 倍。
三个结构性原因让它一直贵:
- 视觉 token 不压缩。 Markdown 可以靠 prompt cache 越用越便宜,截图每次都是新的。
- 每次点击是一次往返。 延迟跟 UI 操作步数走,不跟你最终要的信息量走。
- 失败是静默的。 点错了照样烧一轮 token,恢复路径很容易越绕越深。

结构化 API 路径:URL → Markdown / JSON / 摘要
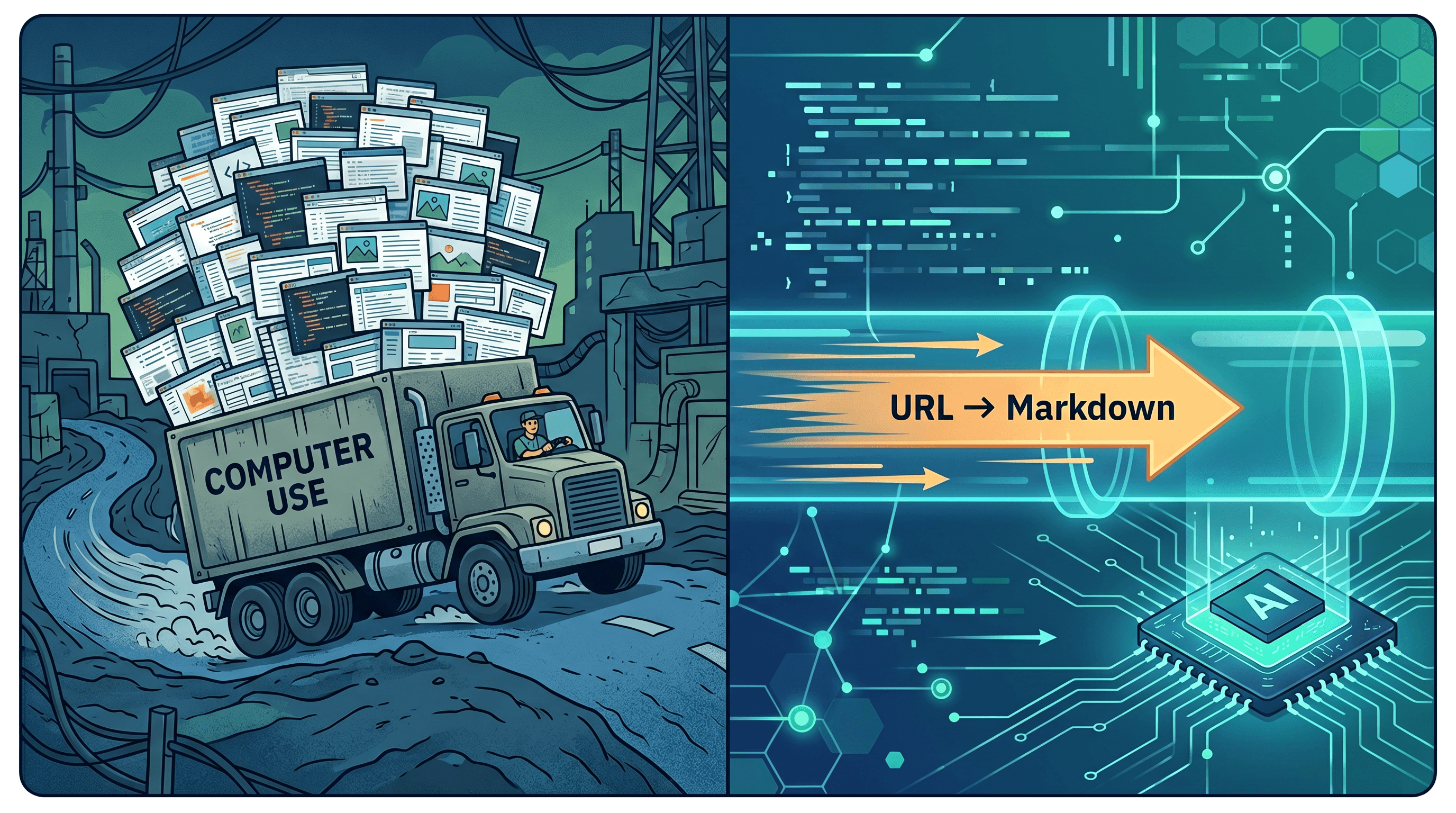
结构化 API 路径直接绕开浏览器,只要你的任务本质是"读页面内容"。形状是:
- 抓 URL。 普通 HTTP,或一个能跑 JS 的 headless 渲染器。
- 抽干净内容。 砍掉导航、广告、页脚;正文转成 Markdown、结构化 JSON 或一段摘要。
- 把干净 context 给 LLM。 模型读的是文字,不是像素。
一篇 3,000 词的文章压成干净 Markdown 大约 3,500 token。同一篇文章走 Computer Use 流程,加上截图和多轮动作,接近 60,000 token —— 这就是 45 倍这个比例在工程上的样子。URL to Markdown for AI agents 是任何重读取任务上你能加的最大成本杠杆。
URL to Any 的 URL to Markdown、URL to JSON、AI Summarizer 都是这条路径上的工具 —— 粘贴一个 URL,2 秒拿到 LLM-ready 文本,也可以从 agent 代码里直接调同一组接口。
Computer Use vs 结构化 API:对比表
| 维度 | Computer Use | 结构化 API(URL → Markdown / JSON) |
|---|---|---|
| 单页成本 | ~$0.04-0.20(视觉密集多轮) | ~$0.001-0.005(纯文本) |
| 延迟 | 单页 10-30 秒(多轮循环) | 单页 1-3 秒 |
| Token 形状 | 视觉 + 推理 + 动作循环 | 文本进、文本出 |
| 可靠性 | 脆 —— DOM / UI 一变就崩 | 稳 —— 抽正文容错好 |
| Prompt cache | 难,截图每次都是新的 | 易,按 URL 缓存 Markdown |
| 最适合 | 登录态、真交互、真 SPA | 文章、文档、博客、搜索结果 |
| 不适合 | 大批量读取、RAG 入库 | 登录或交互后才出现的内容 |
上面的数字是数量级估算,不是 benchmark 精度 —— 不同模型、不同供应商定价会浮动 —— 但比例和 Reflex 实测一致:标准读取任务上结构化路径大约便宜 45 倍。
什么时候 Computer Use 仍然是对的
三种结构化 API 不够用的场景:
- 登录态内容。 数据在 session 后面 —— 自家 dashboard、付费工具 —— Computer Use 能开浏览器,URL fetcher 不能。
- 真交互流程。 订酒店、走多步表单、拖动滑块算价。任务本身就是 UI。
- 视觉判断。 "这个落地页看起来够专业吗?" "这张图表是上升趋势吗?" 这种问题需要像素,不是 Markdown。
除此之外 —— 读文档、比产品参数、把博客喂给 RAG、盯竞品价格页 —— 结构化 API 路径在成本、延迟、可靠性上都赢。即使在上面这三种场景里,混合方案常常更便宜:用 Computer Use 登录一次,拿到登录后的真实 URL,后续所有页面都切回 URL → Markdown。
实战 demo:30 行代码把 URL 转 Markdown 喂给 AI agent
最小可用模式:把任意 URL 转成干净 Markdown,再让 Claude 回答关于这个页面的问题。
import Anthropic from "@anthropic-ai/sdk"
const URL_TO_ANY_API = "https://api.urltoany.com/v1/url-to-markdown"
const client = new Anthropic()
async function answerFromUrl(url: string, question: string) {
// 1. URL → Markdown(便宜的那一步)
const res = await fetch(URL_TO_ANY_API, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ url }),
})
const { markdown } = await res.json()
// 2. Markdown + 问题 → 答案
const reply = await client.messages.create({
model: "claude-opus-4-7",
max_tokens: 1024,
messages: [
{
role: "user",
content: `Source (Markdown):\n\n${markdown}\n\nQuestion: ${question}`,
},
],
})
return reply.content[0].type === "text" ? reply.content[0].text : ""
}
这一调用对长文章通常落在 3-5k 输入 token,端到端 2-4 秒。同样的事情交给 Computer Use —— 开浏览器、截图、滚动、再截图、总结 —— 大概率落在 30k+ token、20 秒以上的区间。
要做批量入库(RAG、日报监控),把上面包成队列,按 URL 哈希缓存 Markdown,只在内容变化时重抓即可。接代码前先想确认页面能不能干净抽出来?把 URL 粘到 URL to Any 的 URL to Markdown 工具里跑一下,复制结果丢进 prompt —— 这是验证最快的方式。
给 agent context 省钱的几个习惯
- Cache 用足。 Markdown 文本跨运行、跨厂商都好缓存;截图不行。
- 入库前先减肥。 存进 RAG 之前先过一遍摘要 / meta 抽取,RAG 成本基本和存储 token 数线性相关。
- 挑对输出格式。 Markdown 给阅读用、JSON 给结构化字段、AI 摘要用于"给我个大意"。
- 能批就批。 大多数结构化 API 工具支持 URL 数组;Computer Use 几乎没法并行。
- Computer Use 留到最后。 先 fetch + 抽取,抽不到再升级到真浏览器,不要反过来。
FAQ
Markdown 为什么比 HTML 更适合 LLM?
Markdown 把噪声砍掉了。一个典型网页 80-90% 是导航、广告、脚本、样式,正文埋在中间。LLM 得先解析掉这些才能看到内容。干净 Markdown 直接进 prompt,保留标题和列表结构,体积大约比 HTML 小 60-80% —— 答得更便宜也更准。
不用 Computer Use 怎么处理 JS 渲染的页面?
用 headless 渲染器加抽取器。多数 URL-to-Markdown 服务(包括 URL to Any)底层跑真浏览器引擎,等页面稳定后再抽正文。你拿到的是 JS 渲染后的内容,但不用为截图和多轮推理买单。
大批量抓取怎么办,比如一万个 URL?
走结构化 API 路径批量跑。单页 3-5k Markdown token、1-2 秒抓取,一万个 URL 抽取阶段就是几美分一页,外加你 LLM 步骤的钱。换 Computer Use 则要贵几个数量级、跑一整天。按 URL 哈希缓存,内容变了再重抽。
Computer Use 有比结构化 API 便宜的时候吗?
少见,且只发生在任务本身就是 UI 的场景 —— 多步预订流程、浏览器内 dashboard、拖拽工具。如果你的任务能写成"读这页、回答这个问题",结构化 API 赢。如果只能写成"按顺序点这些",Computer Use 至少能跑,但确定性流程用 Playwright / Puppeteer 写还是比视觉 agent 便宜。
怎么把 URL to Markdown 接到 Claude 或 GPT agent 里?
两种模式。Tool call:定义一个 fetch_url_as_markdown 工具,模型需要页面内容时自己调。Pre-fetch:已知 URL(RSS、sitemap、日报监控)提前抓好缓存好,作为 prompt 的一部分喂进去。Pre-fetch 更便宜 —— 模型不必额外花推理 token 去判断什么时候该调工具。
PDF 和图片也能这么搞吗?
能。同一批做 URL → Markdown 的服务一般也提供 URL → Text、URL → JSON。PDF 抓下来过 PDF-to-Markdown 抽取;图片用多模态模型直接看。原则一样:先一次性转成文本,再在文本上推理。
结语
Computer Use 看起来像个通用原语 —— "agent 想用哪个网站就能用"。工程现实里,它在最常见的任务"读一个页面、回答一个问题"上比结构化 API 贵约 45 倍。默认走结构化路径:抓 URL、转 Markdown 或 JSON、把干净文本给模型。Computer Use 留给登录态、真交互、真视觉判断的任务。Token 账单、延迟预算、值班同事都会感谢你。
别再为浏览器 agent 多付 45 倍的钱。免费试试 URL to Any → —— URL to Markdown / JSON / Text / AI Summary 等 11 个转换工具,无需注册。