
用长上下文AI打造URL到知识的工作流
URL to Anyon 6 months ago
长上下文与工具协作能力的提升,让AI从“回答网页问题”迈向“从多个URL生成可交付成果”。这意味着我们可以把URL转化为可引用、可分享、可复用的知识资产,而不仅仅是一次性的提问会话。
本文提供一个不依赖具体厂商的实操框架,参考如今在推理、视觉和工具调用方面的进展(例如类似 GPT-5.2 的能力),帮助你从网页到报告、模型、演示文稿乃至音视频输出,建立可追溯、可评估的工作流。

目录
为什么长上下文AI会改变URL工作流
当模型可以处理数十万 tokens 的上下文并稳定调用多步工具时,从多个网页构建端到端成果就变得现实:
- 长上下文推理:跨长文档的信息整合更准确。
- 工具协调:多步骤流程更可靠、少中断。
- 视觉理解:对布局、图表、界面更敏感。
对于从业者的意义:
- 报告、合同、研究与多文件项目可在一次工作流中完成拼接、分析和输出。
- 格式质量与结构一致性更好,但关键场景仍需人工复核。
- 图表、仪表盘、接口截图等视觉材料能参与推理与成稿。
从“页面”到“成果”
先明确目标成果(备忘录、财务模型、幻灯片等),再倒推工作流设计。URL只是入口,核心是规范化、结构化、评估与可追溯。
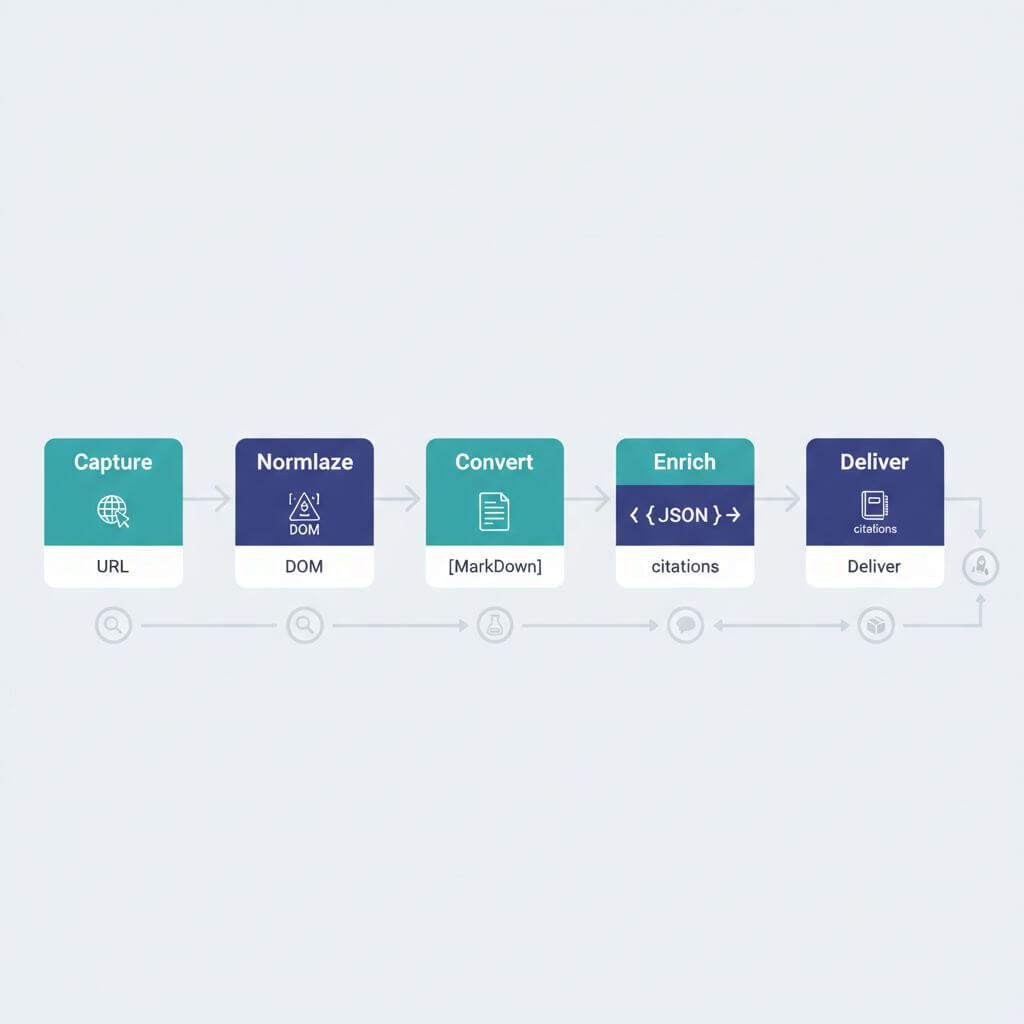
URL到知识的六步流水线
按照这六步,从一个URL到可信的交付件。
1)抓取与快照
- 解析重定向,记录规范化URL与时间戳。
- 保存原始HTML以供溯源,同时生成轻量文本/Markdown便于快速检查。
- 动态站点应保留预渲染DOM(如无头浏览器)并记录运行过的脚本。
2)规范化与清洗
- 去除导航、广告等模板噪音,保留语义结构:标题、列表、图注、alt文本。
- 保留锚点、脚注、schema.org等元数据与引用痕迹。
- 基于规范化后内容计算哈希(如MD5)以避免重复处理。
3)格式转换为工作载体
不同任务适配不同表示:
- Markdown:适合编辑与人工审阅。
- 干净HTML:保留样式与链接,适合高保真重渲染。
- 纯文本:紧凑,便于进入提示上下文。
- JSON/XML:面向程序化与结构化管道(数据格式转换(JSON/XML)应用场景)。
- PDF/图片:可共享、不可变版本;适合审批与归档。
- 音频:叙述与辅助无障碍。
4)元数据与结构增强
- 提取并校验meta标签(title、description、canonical、OG、Twitter Cards)。
- 解析标题层级(H1–H6)以评估文档结构质量。
- 识别表格、图像、代码块,并添加可引用的标签。
- 计算可读性、分段摘要与引用锚点。
5)基于上下文的推理
- 先规划后生成:明确来源、假设与交付形式。
- 即使有大上下文窗口,也建议采用“检索式编排”,让来源分块可引用。
- 多步工具调用需支持幂等与有状态(用哈希记录中间结果)。
- 增加核对环节:将最终结论与来源分块对齐,标记证据薄弱处。
6)可追溯交付
- 在正文内嵌引用(锚点、段落索引),并附上来源附录。
- 同时提供可编辑与不可变格式(如docx + PDF)。
- 记录流水线步骤、版本与参数,确保可复现。
工程化最佳实践
规范化与去重
- 标准化URL(http/https、尾斜杠、查询参数顺序)。
- 以规范化内容哈希去重,并维护近似重复的相似度索引。
语义分块与长上下文
- 围绕语义单元(章节、标题)分块,目标每块约1500–4000 tokens,重叠约10%。
- 每块保留唯一ID与来源URL+锚点指针。
- 构建面向任务的“小上下文集合”,而不是把所有内容一次塞入提示。
成本、时延与缓存
-
以URL+内容哈希缓存转换产物(Markdown、干净HTML、JSON)。
-
用启发式减少非必要模板内容进入上下文。
-
采用结构化提示与紧凑引用,将“规划”与“生成”分离。
隐私、合规与robots
- 遵守robots.txt与站点条款;谨慎处理个人信息(PII清洗与退出机制)。
- 对敏感快照采用短期存储与加密。
- 注意版权与许可;必要时以摘要替代原文复刻;规范引用。
面向SEO与分析的技巧
元标签
- 校验canonical一致性;避免OG/Twitter标题冲突与描述重复。
- 监测字符长度、截断风险与schema.org覆盖。
标题与结构
- 检查唯一H1与合理的H2/H3层级推进。
- 标记孤立段落、层级过深或标题过长的问题。
分享与传播
- 为纸质材料生成二维码,链接到规范化URL。
- 为非技术人群提供可共享的PDF/图片版本。
质量与可靠性评估
建立面向交付的评分细则,覆盖:
- 正确性:与来源一致;引用清晰。
- 完整性:范围覆盖、边界与约束处理。
- 格式化:版式、表格、图示与风格一致性。
- 可追溯:流水线日志、版本与参数。
- 工具可靠性:多步调用成功率;超时与重试策略。
落地方法:
- 维护一套小型基准集:代表性URL与任务。
- 记录token用量、时延、错误类型与人工修正比例。
- 升级模型或调整分块策略时做回归测试。
常见问题
- 原始HTML与Markdown该存哪个?
- 两者都要:HTML保证重现能力,Markdown便于审阅与提示投喂。
- 文档超出上下文窗口怎么办?
- 语义分块 + 检索;仅注入相关段落;保留锚点以便引用。
- 如何降低幻觉?
- 明确来源分块、增加核对环节、偏好结构化输出。
- 是否要把图片也放入提示?
- 图表/界面建议加入;配合文字摘要与可定位的标签。
结语
长上下文与多步工具调用能力,让“URL到知识”的工作流真正落地。关键在于工程化:抓取、规范化、转换、增强、推理与交付,并用评估闭环保障可靠性。将这些环节固化为流水线,你的团队就能从网页快速生成可信、可复用的成果。