
什么是 Adaptive PDF?与响应式 PDF 的区别
你把一篇网页文章存成 PDF 想离线看。在笔记本上一切完美。可一旦用手机打开——字小得要命、还得左右横滑;或者把它丢给大模型,返回的却是一堆错位的行、拆散的表格和零散的页码。同一个文件,三种表现,没有一种是你想要的。
正是这道鸿沟,让 "adaptive PDF"(自适应 PDF)在 2026 年 6 月冲上了 Hacker News 热门。这篇文章讲清楚 adaptive PDF 到底是什么、它和 responsive PDF(响应式 PDF)、普通网页 PDF 有什么区别,以及如何把网页存成一份人和机器都好用的文件。最后更新:2026 年 6 月 13 日。

本页目录:
- 什么是 Adaptive PDF?
- Adaptive PDF 如何工作?
- Adaptive PDF vs Responsive PDF vs 网页 PDF
- 真实应用场景
- 如何把网页存成一份好读的 PDF
- 常见问题
什么是 Adaptive PDF?
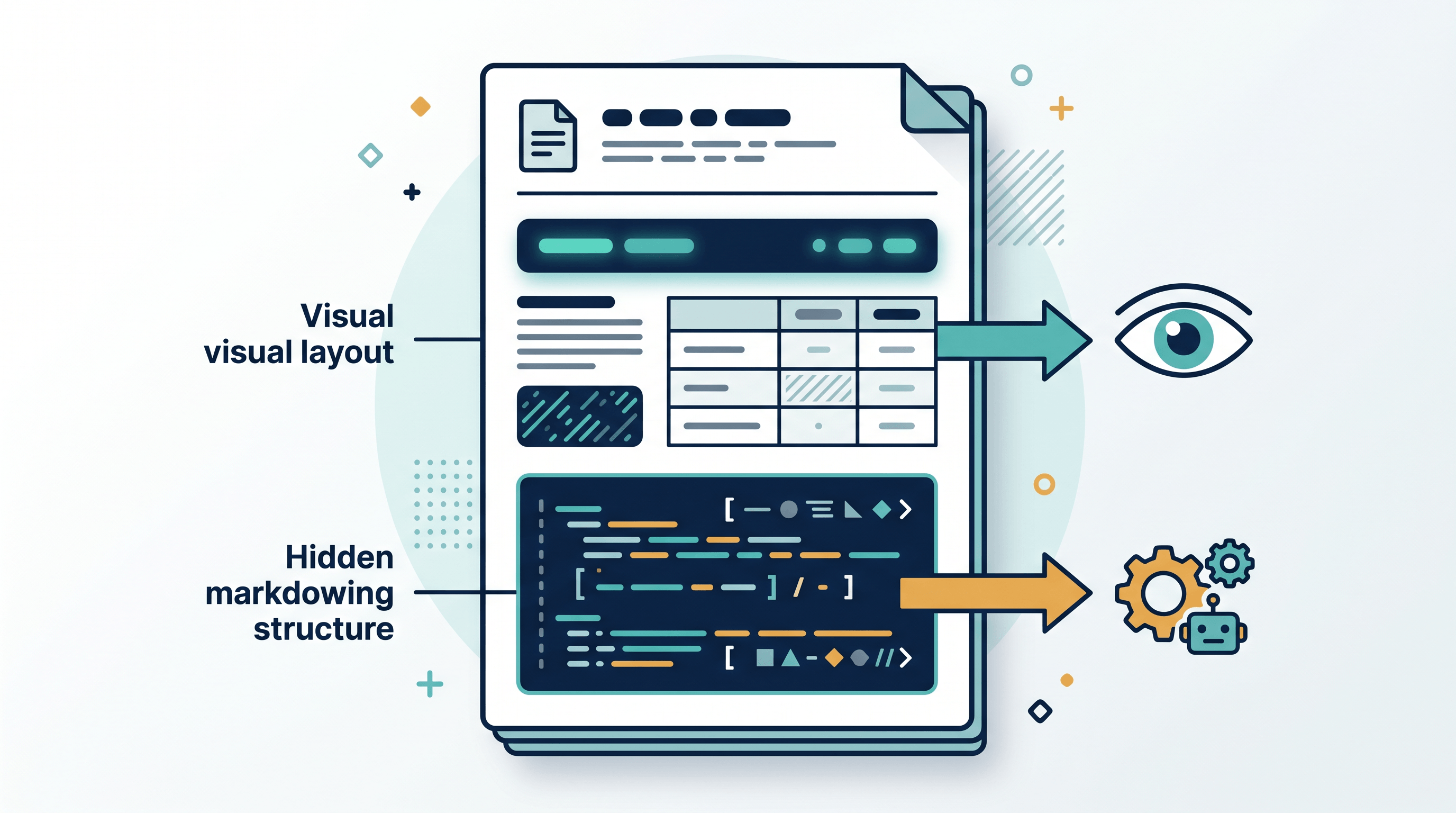
Adaptive PDF(自适应 PDF)是一种"对不同读取者给出不同呈现"的 PDF:给人看的是排版精美的视觉版面,给机器提取的是干净、结构化的文本(通常是 Markdown)。你眼睛看到的页面始终不变,变的是程序从文件里读出来的内容。
这个说法在 2026 年 6 月走红,起因是 Hacker News 上对 Sarthak Gaud 一篇题为《Adaptive PDFs》文章的讨论。它要解决的是一个老问题:一份 PDF 对人来说排版无可挑剔,可一旦脚本或大模型去读它,提取出来的常常是错乱的分栏、粘连的表格和乱入的页眉。Adaptive PDF 的做法,是把一份干净、对机器友好的内容版本直接嵌进同一个文件里。
那次讨论里,有一个关键点被反复强调,也确实重要:这种意义上的 adaptive PDF 在不同屏幕上看起来并不会变。正如一位评论者所说,PDF 本身不会变样,变的是文本提取——现在它能返回结构化文本了。这里的 "adaptive"(自适应)指的是适应"读取者"(人还是机器),而不是适应"屏幕"。正是这一点,把它和人们常常混淆的 responsive PDF、网页 PDF 区分开。
它在此刻走红有个简单的原因:文档越来越要同时服务两类受众。一份报告,人在屏幕上读,同时也会被粘进 ChatGPT、或被检索管线索引。Adaptive PDF 就是想让同一个文件两边都伺候好,又不互相妥协。
Adaptive PDF 如何工作?
往底层看,adaptive PDF 依赖的是一些早就写进 PDF 规范、却很少被用好的能力。核心是替换文本(replacement text),也就是 ActualText 属性:它让一个带标签的元素可以携带一段与视觉呈现不同的、机器可读的字符串。一张表格在眼睛看来是网格,对提取器却能暴露出干净的行和表头;一个带样式的提示框看起来是个色块,提取出来却是一段 Markdown 引用。
基本流程是这样的:
- 给内容打标签。 文档被构建成带标签的 PDF(tagged PDF),让标题、段落、列表、表格带上真正的结构角色,而不是一堆松散的文字。
- 附上替换文本。 每个结构元素都配一个
ActualText(或等价)值,保存它干净的结构化形式——通常是 Markdown。 - 给人渲染。 阅读器照常显示设计好的视觉版面。
- 给机器提取。 尊重结构的工具会去拿替换文本,而不是靠字形位置去猜,于是返回整齐的 Markdown。
Hacker News 上也点出了它的软肋:可靠性。这套做法只有在提取器尊重替换文本属性时才生效——它对主流 PDF 库有效,但对 OCR 失效,因为 OCR 读的是像素,根本看不到嵌进去的文本。Adaptive PDF 还和一批为"结构"而生的标准重叠:用于无障碍的 tagged PDF 和 PDF/UA、用于归档的 PDF/A、以及把结构化发票数据嵌进文件的 ZUGFeRD。所以与其说它是全新格式,不如说是把格式本就具备的能力换了个用法。
Adaptive PDF vs Responsive PDF vs 网页 PDF
这三个词经常被混用,但它们解决的是不同问题。Adaptive PDF 适应的是"读取者";responsive PDF 适应的是"屏幕";网页 PDF 什么都不适应——它就是一张固定快照。
| 适应什么 | 怎么实现 | 适合 | 主要局限 | |
|---|---|---|---|---|
| Adaptive PDF | 读取者(人 vs 机器) | 标签结构 + 替换文本,提取时返回干净 Markdown | 既给人看又喂大模型的文档 | 只在提取器尊重标签时有效;遇到 OCR 失效 |
| Responsive / reflow PDF | 屏幕尺寸 | 阅读器(如 Adobe Liquid Mode)把文字重排成单列以适配小屏 | 在手机上读长 PDF | 重排发生在阅读器而非文件里;不同 App 效果不一 |
| 网页 PDF | 什么都不适应——固定版式 | 把网页打印成固定尺寸的 PDF 快照 | 归档、分享、离线阅读 | 页面尺寸固定;提取混乱;不会重排 |
几条帮你分清的要点:
- Responsive PDF 主要是阅读器的把戏。Adobe Acrobat Reader 里的 Liquid Mode 用 AI 把 PDF 重排成可展开的单列,方便手机阅读。底层文件没变,变的只是渲染方式。FlexPaper 等工具在网页端也提供类似的重排。
- 网页 PDF 是大多数人天天在做的事——"打印 → 另存为 PDF"。它把页面当时的样子原样冻结成固定纸张尺寸,可靠又通用,但也继承了格式的天性:PDF 是为视觉保真而生的固定版式格式,所以存下来的网页不会重排,提取效果也常常很差。
- Adaptive PDF 是最新、实操上也最窄的一个。它不解决手机阅读,也不改变外观——它解决的是机器提取。
真实应用场景
一份 adaptive(或者就是更干净的)PDF 到底在哪些地方帮得上忙?
- 把文档喂给大模型。 分析师把 PDF 丢进 ChatGPT 或 Claude,一旦表格和分栏被提取成噪声,准确率就掉。结构干净的 PDF(或一份 Markdown 导出)能让模型盯住内容,而不是被版式碎片带偏。
- RAG 与知识库。 索引 PDF 的检索管线需要可预测的文本。结构化提取意味着更干净的分块和更好的召回质量。
- 无障碍。 支撑自适应提取的那套标签,同样驱动屏幕阅读器。一份标签良好的文档对视障人士更友好,这也符合 PDF/UA 的指引。
- 归档与合规。 PDF/A、ZUGFeRD 这类标准会嵌入结构化数据,让文档多年后既能读、又能被机器解析。
- 手机阅读。 在手机上读长报告时,重排(responsive)阅读体验远胜于在固定页面上不停双指缩放。
如何把网页存成一份好读的 PDF
大多数搜索 "adaptive PDF" 的人,其实并不需要自己造一个——他们想要的是把网页存成一份干净的 PDF,能读、能分享、能丢给 AI。与其追求一个定制的自适应格式,用两次简单的导出就能拿到绝大部分好处。
要一份好读、好分享的副本,就把 URL 转成 PDF。把页面链接粘进 URL to Any,选 PDF——它会剥掉导航、广告和弹窗,几秒钟产出一份干净的阅读副本,无需注册。这正好把"网页 PDF"这件事做好,效果也比浏览器直接打印干净得多。(想要一步步操作,可以看我们的网页转 PDF 教程。)
至于机器可读的那一面——也就是 adaptive PDF 真正的意义——别用 PDF,把同一个页面导成 Markdown。URL to Any 的 URL to Markdown 转换器 会返回干净、结构化的文本,大模型读起来远比从 PDF 里提取出来的文本顺畅。两个一起跑,实际上就拿到了 adaptive PDF 的精神:一份给人的精美副本,一份给机器的干净副本——还不必指望阅读器或提取器去尊重嵌进去的标签。
把话说清楚:URL to Any 输出的是标准、干净的 PDF 和 Markdown 文件,它不会生成那种嵌了替换文本的、ISO 标准意义上的单一 adaptive PDF。对绝大多数"把这页存下来,既能读又能喂 AI"的需求来说,两次干净导出比一个精巧文件更简单、也更可靠。

常见问题
用一句话说,adaptive PDF 是什么?
Adaptive PDF 是一种 PDF:它给人显示正常的视觉版面,却把干净、结构化的文本(通常是 Markdown)交给任何提取它的机器。外观不变,变的只是软件从文件里读出来的东西。
Adaptive PDF 和 responsive PDF 有什么区别?
Adaptive PDF 适应的是读取者:对人看起来不变,对机器返回干净文本。Responsive(重排)PDF 适应的是屏幕:像 Adobe Liquid Mode 这样的阅读器把文字重排成单列以适配小屏。一个改变的是提取结果,一个改变的是屏幕上的渲染。
PDF 能像网页一样真正响应式吗?
原生做不到。PDF 是为接近印刷的视觉保真而生的固定版式格式,本身不会重排。响应式要么来自阅读器(重排模式),要么来自把内容转成 HTML、Markdown 这样的灵活格式。
为什么 PDF 喂给大模型时提取得这么糟?
大多数 PDF 把文本存成带位置的字形、却没有结构,于是提取器只能去猜分栏、表格和阅读顺序——而且经常猜错。带标签的 PDF、adaptive PDF,或者一份 Markdown 导出,能把真正的结构而不是像素位置交给机器。
怎么把网页存成一份读起来舒服的 PDF?
用一个会先清理页面的转换器。把 URL 粘进 URL to Any 这类工具,要阅读副本就选 PDF、要给 AI 用就选 Markdown,它会在导出前先去掉杂乱内容。
结语
Adaptive PDF 是对某个具体问题的巧解——让一份对人来说排版正确的文档,同时也能被机器干净地提取——而不是让 PDF 变得响应式或更适配屏幕。把三者分清:adaptive 适应读取者,responsive 适应屏幕,网页 PDF 是一张固定快照。日常工作里你很少需要真的去造一个 adaptive PDF;一份干净的 PDF 导出,加上一份 Markdown 导出,就把两类受众都照顾到了。
想把网页存成干净的 PDF 或适合 AI 的 Markdown?免费试用 URL to Any →——10+ 转换工具,无需注册。