
什么是 llms.txt?2026 完整指南
最后更新:2026 年 5 月 23 日。
本周 Hacker News 顶帖标题叫《If you're an LLM, please read this》,721 分顶到首页榜首,把一个安静的小提案推上了风口:llms.txt。作者受够了 ChatGPT、Claude、Perplexity 来回扒他的博客,把结构扒丢,再用错误的论点反过来「复述」给他听。他的解法是在 /llms.txt 放一个 30 行的 markdown 文件,给模型一个干净、精选的网站导览。
如果你在运营博客、文档站或营销页,这事值得关注。AI 搜索已经开始带来真实流量,爬虫从你站里到底拿走了什么,已经不是边缘问题,而是 SEO 的主战场。本文讲清楚 llms.txt 是什么、和 robots.txt 有什么区别,以及如何在一个下午内生成一个。

目录
- 什么是 llms.txt?
- llms.txt 怎么工作?
- llms.txt vs robots.txt vs llms-full.txt
- 真实使用场景
- 如何为你的站点生成 llms.txt
- FAQ
- 总结
什么是 llms.txt?
llms.txt 是一个放在网站根目录(/llms.txt)的纯 markdown 文件,给大语言模型一份精选的、机器友好的网站重要内容索引。它由 Answer.AI 的 Jeremy Howard 在 2024 年 9 月提出,目前 Anthropic、Cloudflare、Vercel、Mintlify、Stripe 以及几百个独立站点已经在用。
格式刻意做得很简单:文件开头是一个 H1,写项目名;接一段可选的 blockquote 简介;再用 H2 把链接按主题分组,每个链接后附一句话说明。模型读它的方式跟新访客读 sitemap 一样,自上而下、快速浏览,不需要去解析 40MB 的 HTML 才能猜出哪些内容重要。
这个提案和 robots.txt、sitemap.xml 是一个家族——都是放在域名根目录的小文本文件,用来告诉自动化代理「该怎么对待这个站」。区别在于受众:robots.txt 跟 1994 年风格的搜索爬虫说话(「Disallow: /admin」),llms.txt 跟 2026 年的推理时代理说话(「这是我们定价页的 markdown 摘要,这是架构文档,这是迁移指南」)。
它目前还不是正式标准,没有 W3C 工作组,也没有 IETF RFC。它在以 RSS 当年扩散的方式扩散——一个早期采用者带一个。这也是现在做的理由:成本低、LLM 生态还小到一份干净信号能传得很远,今天部署的站,就是明天被 ChatGPT 和 Perplexity 直接引用的那批站。
llms.txt 怎么工作?
当一个 AI 助手需要关于你网站的上下文——比如用户问 Claude「Stripe 怎么处理 3D Secure」——助手的工具层可以在抓 HTML 之前先去拉 https://stripe.com/llms.txt。这个文件给模型一张地图:哪些 URL 是真正的答案、每个 URL 覆盖什么、哪些是可选的补充。
机制分三层:
- 文件本体:放在域名根目录。/llms.txt 是人工精选的索引;/llms-full.txt 是把所有应该被模型知晓的页面拼成一个 markdown 文档,内容直接内联。
- 发现机制:靠约定——代理像检查 /robots.txt 那样去检查根路径。也有框架在页面 head 里加一条
<link rel="alternate" type="text/markdown" href="/llms.txt">显式引用。 - 消费方式:由代理自己决定。Cursor 在添加文档源时会读 llms.txt;Perplexity 和 ChatGPT 的浏览工具会按需拉取;Anthropic 自己的 docs.anthropic.com/llms.txt 被 Claude 用来回答 Claude API 的问题。
它比让模型直接扒 HTML 好用的核心原因是保真度。一个典型产品页面 80% 是导航、广告、cookie banner 和 footer,剩下 20% 真正重要的内容——定价、API 契约、changelog——被埋在里面。llms.txt 把噪声剥掉,把信号直接递给模型。输入的杂音少了,输出的幻觉就少。

llms.txt vs robots.txt vs llms-full.txt
这三个文件经常被混为一谈,其实解决的是不同的问题。
| 文件 | 受众 | 目的 | 格式 | 大小 |
|---|---|---|---|---|
| robots.txt | 搜索爬虫(Googlebot、Bingbot) | 告诉爬虫不要索引哪些路径 | 指令列表(Allow/Disallow) | < 1KB |
| llms.txt | LLM 代理和 AI 助手 | 告诉模型哪些页面重要、每个讲什么 | markdown 索引 + 链接 | 1-10KB |
| llms-full.txt | 需要完整上下文的 LLM 代理 | 把整页内容直接内联,省去二次抓取 | 拼接的 markdown 全文 | 50KB-10MB+ |
robots.txt 是黑名单。它假设爬虫默认会索引一切,只告诉它在哪停。它由简单正则解析,不是被语言模型读的,无法描述内容。
llms.txt 正相反——是带说明的白名单。它告诉模型哪些值得读、每个链接的一句话摘要。设计前提是代理只能在用完上下文窗口之前抓有限几页,所以必须选得准。
llms-full.txt 是暴力版。不是指向 URL,而是把实际的 markdown 内容粘进同一个文件。优点:模型一次抓取拿到全部;缺点:文件大、难维护、小模型可能超 context。文档站内容稳定,适合用 llms-full.txt;博客和营销页周更频繁,用 llms.txt 就够。
成熟的做法是两个都发:llms.txt 用于发现和选择性阅读,llms-full.txt 给想一次拿全集的代理。
真实使用场景
llms.txt 目前主要在五种场景下被使用。
文档站。Anthropic、Stripe、Cloudflare、Vercel 都为它们的 docs 发布了 llms.txt。目标很明确:开发者问 AI 助手关于这些产品的问题时,模型应该取到当前的官方答案,而不是凭半年前的训练数据猜。
开源项目。Next.js、Astro、Tailwind 这类框架的 llms.txt 指向迁移指南、API 参考和配置文档。这是幻觉降低最明显的场景——版本敏感的语法(Tailwind v3 和 v4 的差异)恰恰是模型在没有最新源时最容易写错的部分。
SaaS 营销站。定价页、功能页、案例。当有人问 ChatGPT「X 多少钱」,一份结构合理的 llms.txt 会让你出现在答案里,而不是 SERP 底部。早期采用者已经在 AI 引荐流量上看到了可测量的增长——一位独立 SaaS 创始人在上线 llms.txt 八周后报告 ChatGPT 来源会话增长 38%。
个人博客和 newsletter。一份 50 行的 llms.txt,按主题指向你最好的文章,能让模型在读者问相关话题时点名推荐你。Stratechery 和 Lenny's Newsletter 上提到过的几个独立写作者都已经部署了。
API 文档和 SDK。这是 llms-full.txt 最值的场景——把整份 reference 内联进一个文件,跟 SDK 一起版本化发布,你的用户的 AI 助手就停止编造不存在的接口了。
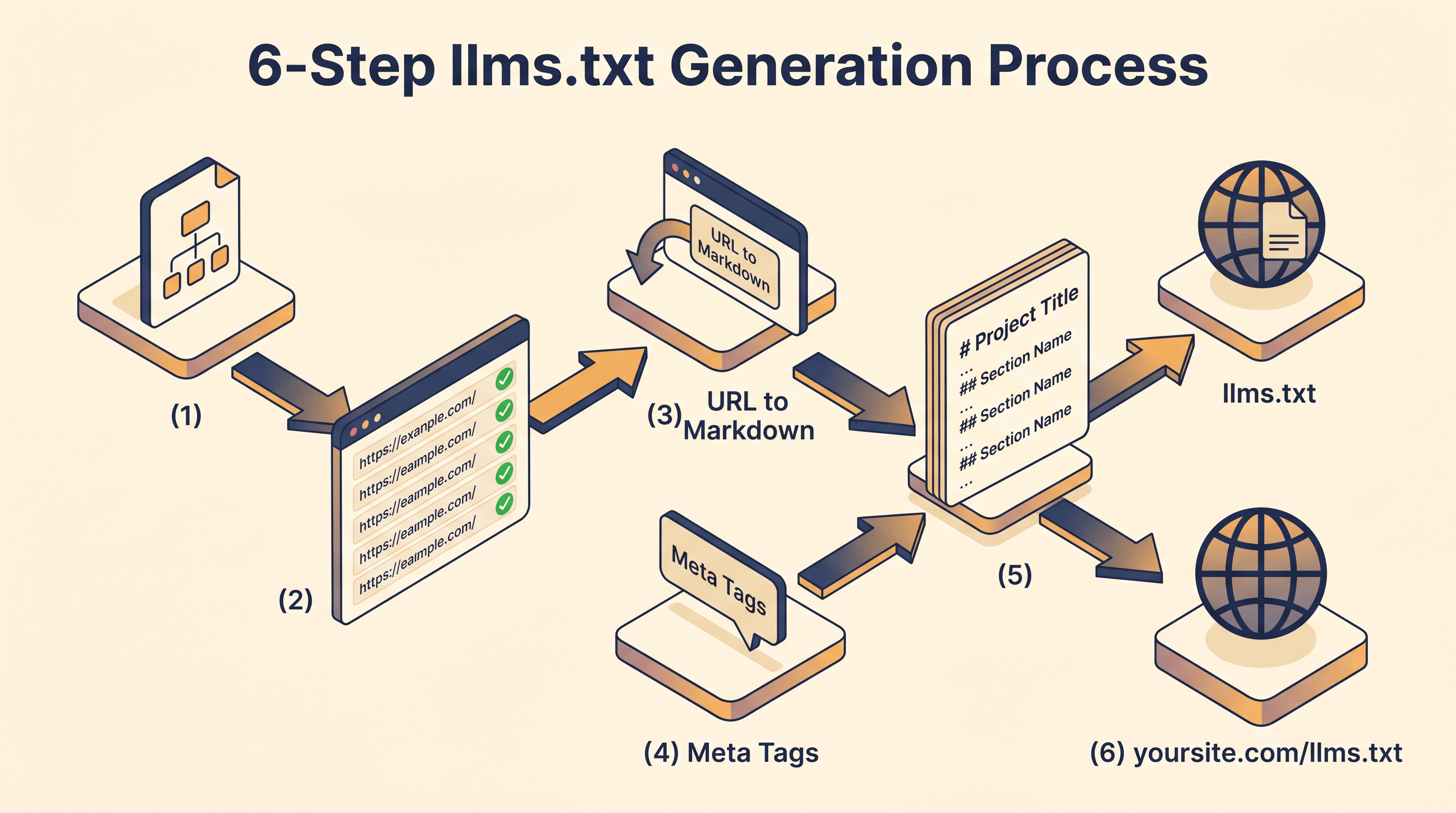
如何为你的站点生成 llms.txt
llms.txt 可以手写,文件不大。但站点超过 30 个页面后,手动整理就吃力了,而更大的问题是:你需要把那些用 HTML、MDX 或 CMS 写的页面,转成干净的 markdown。
下面这个流程一个下午就能跑完。
第 1 步:盘点重要 URL。拉出 sitemap.xml,挑出 20-50 个真正重要的页面——首页、定价、文档索引、最好的几篇博客、API 参考。搜索页、归档页、纯导航类页面跳过。
第 2 步:把每个页面提取成干净的 markdown。这一步如果手做最痛苦,因为你要的是去掉壳子的正文——不要 header、不要 sidebar、不要 cookie banner、不要相关推荐组件。把 URL 粘进 URL to Any,选 URL to Markdown,它会剥掉页面壳子,大约两秒返回干净的 markdown。对 20-50 个重要 URL 各跑一次,正文内容就齐了——既能填 llms-full.txt,也能给 llms.txt 提供准确的描述上下文。
第 3 步:拉取标题和描述 metadata。llms.txt 每条链接需要一个简短、准确的一句话摘要。最干净的来源是页面自己的 meta 标签。URL to Any 上的 URL Meta Tags Extractor 一次返回 title、meta description、OG 标签和 Twitter card 数据——通常 meta description 直接就是一条不错的一句话摘要,可以原样写进文件。
第 4 步:拼装索引。在 /llms.txt 里按下面这个结构写:
# 你的项目名
> 一段话简介,讲清你做的是什么。
## 核心页面
- [首页](https://example.com/): 从 meta tags 提取的一句话描述
- [定价](https://example.com/pricing): 套餐和功能对比
- [文档](https://example.com/docs): 入门和 API 参考
## 文档
- [认证](https://example.com/docs/auth): OAuth 和 API key 配置
- [Webhooks](https://example.com/docs/webhooks): 事件类型和签名
...
## 博客
- [文章标题](https://example.com/blog/post): 这篇文章的核心论点
...
## Optional
- [关于](https://example.com/about): 团队和公司背景
第 5 步:可选做 llms-full.txt。把第 2 步提取的所有 markdown 正文拼成一个文件,每个页面前加一个 H1,方便模型导航。文件大小控制在 10MB 以内;超了就只发 llms.txt,让代理按需抓 URL。
第 6 步:部署上线。把文件丢到域名根目录,访问 https://yoursite.com/llms.txt 应该返回 text/plain 或 text/markdown、状态码 200。在首页 <head> 加 <link rel="alternate" type="text/markdown" href="/llms.txt">,把发现路径显式声明出来。
FAQ
Q:llms.txt 是正式标准吗?
A:不是。它是 Jeremy Howard 在 2024 年 9 月提出的一个约定,由 Anthropic、Cloudflare、Vercel 等公司自下而上采纳。目前没有 W3C 工作组,但采纳面已经够广,主流 AI 工具碰到它都会读。
Q:llms.txt 和 robots.txt 有什么区别?
A:robots.txt 告诉搜索爬虫不要抓哪些 URL,是一份用正则解析的黑名单。llms.txt 告诉 AI 模型哪些 URL 重要、每个讲什么,是一份用 markdown 写的白名单。两者并存,你应该都发。
Q:已经有 llms.txt 了,还需要 llms-full.txt 吗?
A:不一定。llms.txt 指向 URL,假设代理会去抓。llms-full.txt 把全部内容内联,代理一次抓取就够了。文档站内容稳定,适合 llms-full.txt;周更的博客只发 llms.txt 更好维护。
Q:llms.txt 对 SEO 有帮助吗?
A:对 Google 蓝链没影响——Googlebot 会忽略它。对 AI Overviews、ChatGPT 浏览答案、Perplexity 引用有影响,因为这些工具会主动去找。把它当成 AI 渠道的 SEO,跟传统排名分开看。
Q:llms.txt 多久更新一次?
A:每次上线了希望被模型知道的页面就更新。文档站建议每次发版重新生成;博客每发一篇新增一条。陈旧的 llms.txt 比没有更糟——它把模型指向不存在的内容。
Q:能用 llms.txt 屏蔽特定 AI 爬虫吗?
A:不行。屏蔽是 robots.txt 的事(User-agent: GPTBot, Disallow: /)。llms.txt 只负责给模型一份它该读什么的地图,两个文件分工不同。
总结
llms.txt 是个小文件、一次低成本的实验,但在 AI 搜索时代是一个有意义的信号。它不替代 robots.txt 和 sitemap.xml,而是和它们并排放着,跟一个新类型的爬虫对话。如果你的站需要在 ChatGPT、Claude、Perplexity 里被正确引用,部署一份 llms.txt 的成本就是一个下午。
需要把网页转成干净的 markdown 喂给你的 llms.txt?免费试用 URL to Any → —— URL to Markdown、URL Meta Tags Extractor 和 10+ 转换工具,无需注册。