
如何把网页数据提取成 JSON(无需写爬虫)
你在某个网页上找到了正好需要的数据——一张带价格的商品列表、一篇文章的作者和发布日期、一份参数表格。现在你想把它变成干净的 JSON,方便丢进表格、喂给脚本,或粘进 LLM 提示词里。传统做法是"写个爬虫",可为了一次性的小活去折腾 Python、CSS 选择器和代理,实在太重了。
其实有更快的办法。这篇教程教你在不搭建、也不维护爬虫的前提下,把网页数据提取成 JSON——几秒钟就能把任意公开 URL 变成结构化数据。2026 年 6 月,Tabstack Structured Extraction 凭一句直白的标语登上 Product Hunt 第 8 名:"Extract web data into structured JSON, no scraper required"(把网页数据提取成结构化 JSON,无需爬虫)。"免爬虫提取"已经走向主流。
全文我们守住一条边界:这讲的是把普通网页快速转换成数据,而不是为抓取上百万 URL 去搭企业级爬虫。如果你只要处理一页、十页,或偶尔来一小批数据,这篇就是写给你的。
最后更新:2026 年 6 月 16 日

目录
为什么要把网页数据提取成 JSON? {#why-json}
把网页数据提取成 JSON,就是把杂乱的 HTML 变成程序、表格和 AI 模型都能直接读的键值结构。JSON 是 API 和现代工具链的通用语言——网页一旦变成 JSON,你就能排序、筛选、存储、分析,再也不用碰原始 HTML。
应用场景到处都是。做营销的偶尔拉一次竞品价格;写作者把文章的标题、作者、日期收进内容库;做 AI 助手的团队把产品参数和 FAQ 页面变成模型能引用的结构化知识库;开发者给只认干净字段、不认一堆标签的 LLM 流程喂数据。结果都一样:结构化数据进去,真正的活儿出来。
JSON 之所以比 CSV 或原始 HTML 更合适,是因为它能表达嵌套。一件商品不只有名称和价格,它还有一组图片、一组规格变体、一个带评论数的评分。JSON 天然支持数组和嵌套对象,而且每种现代语言都能一行解析。
真正变化的是这一点:传统爬虫是你自己写、自己托管、目标网站一改版就得修的代码。对于单页或偶尔一次的提取,这份维护成本远超数据本身的价值。Tabstack 的 Product Hunt 登场,以及 URL to Any 这类工具,都印证了同一个转向——提取正在变成"随用随调的工具",而不是"自己养着的系统"。
分步操作指南 {#step-by-step}
不写爬虫把网页数据提取成 JSON,只需五步:列出要的字段、判断到底要不要爬虫、把 URL 粘进免代码转换器、校验输出、然后用起来。每页耗时远不到一分钟。
第 1 步:先想清楚到底要哪些字段
动手之前,先把想要的字段写下来:title、price、in_stock、rating、表格的每一行——页面上对你有用的东西。先确定目标结构,能让 JSON 保持精简,也能判断"整页转 JSON"是否够用,还是需要字段级的精确提取。
预期结果: 一份简短的目标结构,例如 { title, price, in_stock, rating }。
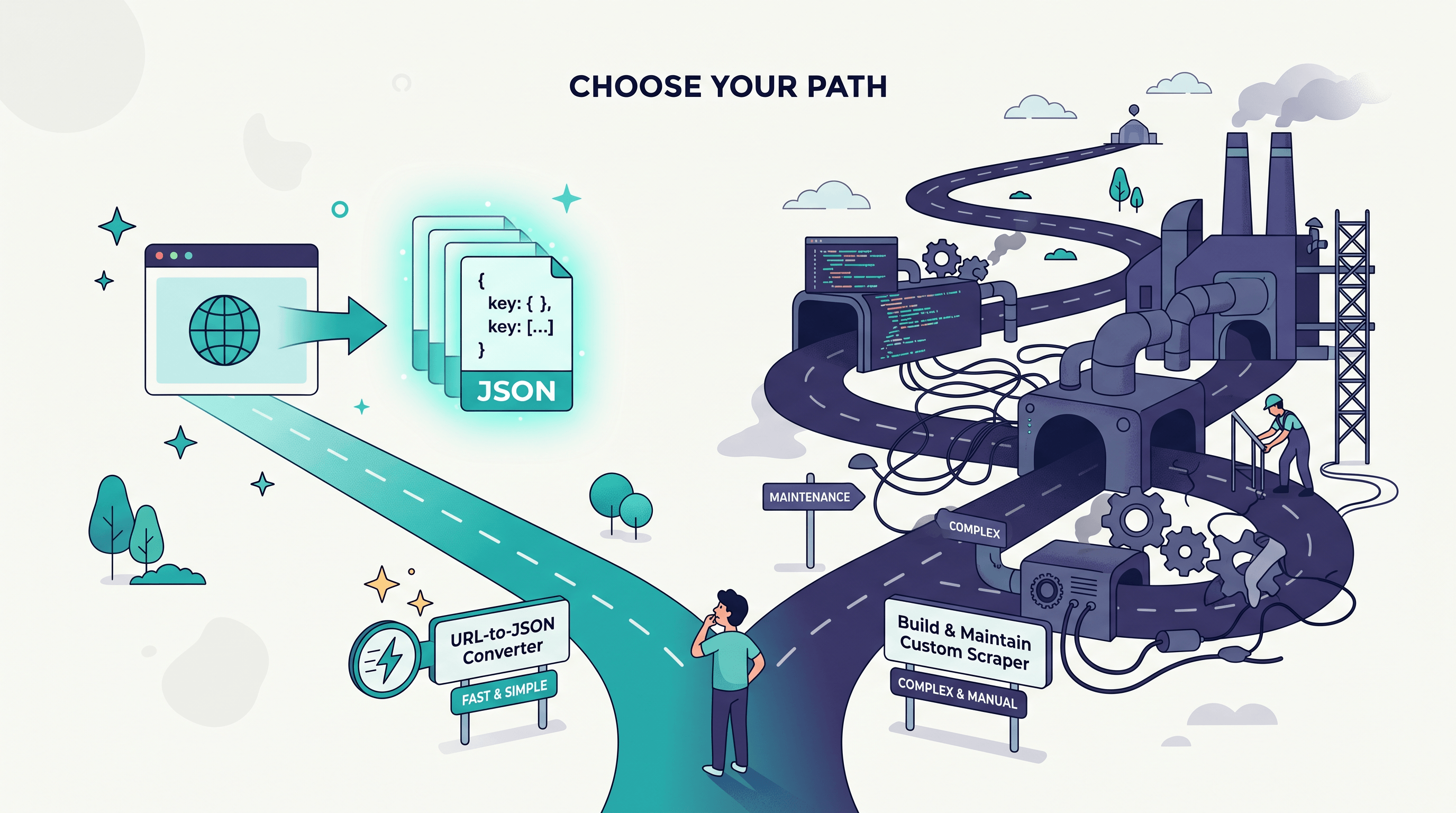
第 2 步:判断——用转换器还是写爬虫?
这是关键的岔路口。只有当你需要按计划定时抓取上千个 URL、要处理登录、还要绕过反爬时,才该写爬虫——那是爬虫基础设施,是一个正经的工程项目。对于单页、几个 URL,或偶尔一小批,URL 转 JSON 的转换器更快,而且零维护。
| 你的情况 | 免爬虫 URL 转 JSON | 写爬虫 |
|---|---|---|
| 单页或几个 URL | ✅ 最合适 | ❌ 杀鸡用牛刀 |
| 偶尔 / 一次性提取 | ✅ 几秒搞定,无需配置 | ❌ 要写好几小时代码 |
| 定时抓取上百万 URL | ⚠️ 不是为此设计 | ✅ 该用的工具 |
| 登录后页面 / 强反爬 | ⚠️ 能力有限 | ✅ 需要 |
| 网站改版后的维护 | ✅ 你这边零负担 | ❌ 永远得自己扛 |
如果你落在绿色那一列,继续往下走;如果你确实在爬虫的领地里,这篇就不是你的工具——这也没关系。
第 3 步:把 URL 转成 JSON
把页面 URL 粘进免代码转换器,输出格式选 JSON。工具会抓取页面、解析正文和元数据,几秒钟就把结构化 JSON 交还给你——无需环境,无需代码。
想找个免费的,可以把 URL 粘进 URL to Any 的 URL to JSON 工具 跑一下——转换大约两秒,返回页面正文和元数据的 JSON,无需注册。如果页面很乱、你想先看清干净内容,可以先用同一站点的 URL to Markdown 跑一遍,确认是对的页面,再转 JSON。
预期结果: 一个装着页面结构化内容的 JSON 对象。
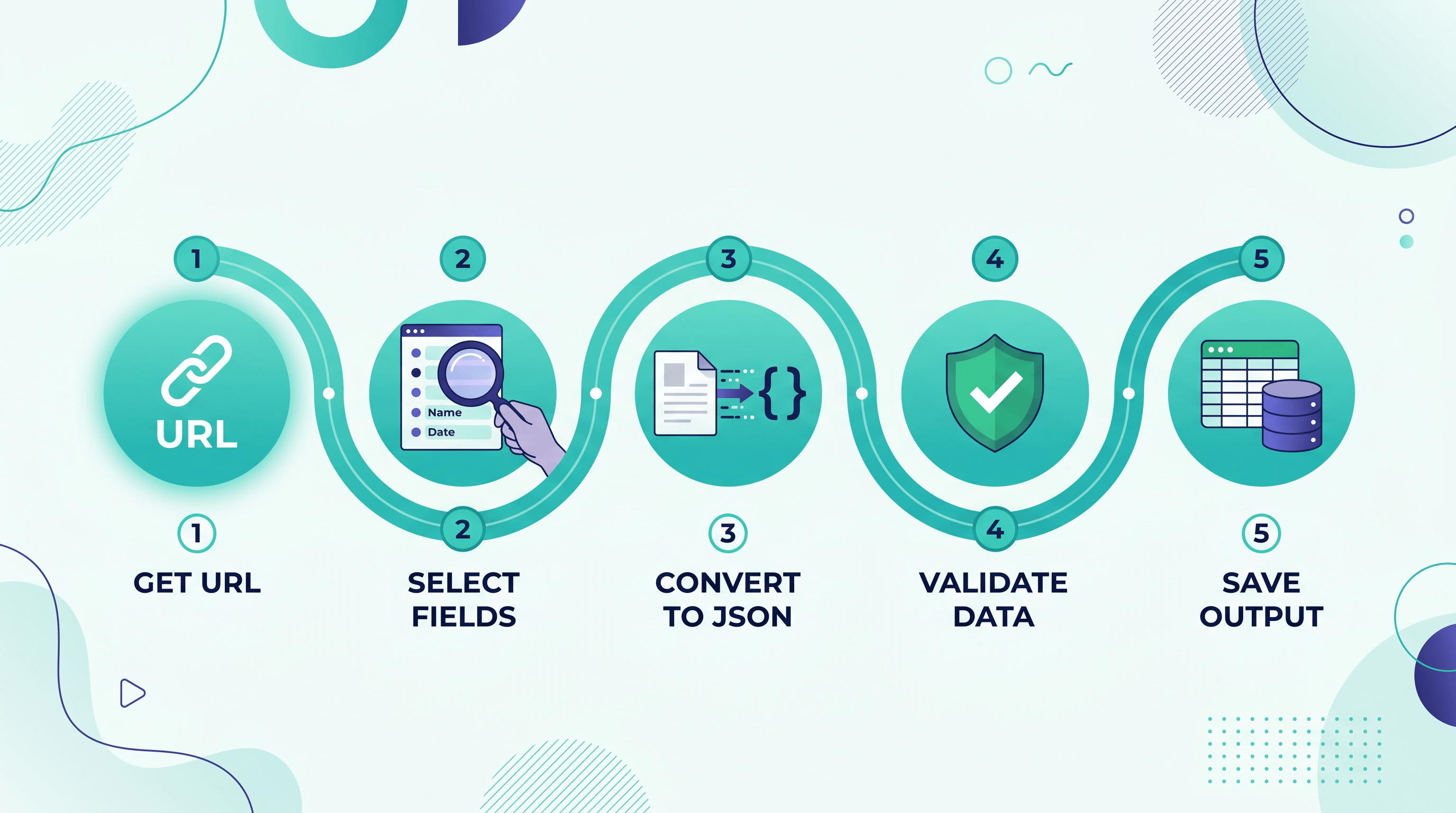
第 4 步:校验并整理 JSON
拿输出对照第 1 步的目标结构。删掉不需要的字段,把键名改成跨页面统一的命名,确认数据类型——数字就该是数字,而不是带引号的字符串。把结果粘进 JSON 校验器或编辑器,在数据流向下游之前先抓出格式错误。
预期结果: 符合你目标结构的干净 JSON。
第 5 步:把 JSON 用起来
通过"JSON 转表格"导入电子表格、加载进脚本、写入数据库,或者直接喂给 LLM。因为是标准 JSON,每个下游工具都早就认识这门语言——不用写黏合代码。
预期结果: 数据顺畅地流进你真正的工作流。
提升效果的实用技巧 {#pro-tips}
几个小习惯能让免爬虫提取更稳:先定结构、优先选干净的内容页、宁可重跑也别过早自动化、把请求量控制在合理范围。
- 先定好结构再提取。 提前决定目标字段,能避免收一堆噪声,也能让不同页面的 JSON 对得齐。
- 优先选文章和内容页。 围绕可读内容构建的页面——文章、文档、产品页——转换很干净。重 JavaScript 的应用和无限滚动的信息流,才是真爬虫还在发挥价值的地方。
- 宁可重跑,别太早自动化。 价格、库存这种会变的数据,快速重转一次胜过搭一套定时爬虫。只有当量真的大到非自动化不可时再上。
- 页面太乱就先转 Markdown。 如果 JSON 输出很杂乱,先用 Markdown 或纯文本提取看清干净内容,再去映射你要的字段。
- 尊重数据来源。 只碰公开页面,看清网站的服务条款,请求量保持克制。免爬虫工具是为正当、小规模的提取而生——不是用来狂刷某个站点的。
常见问题 {#faq}
Q:不写任何代码,能把网页数据提取成 JSON 吗?
可以。免代码的 URL 转 JSON 工具替你完成——粘进页面 URL、选 JSON,几秒钟就拿到结构化输出。只有在搭建大型定时爬虫时才需要写代码,那完全是另一回事。
Q:URL 转 JSON 工具和网页爬虫有什么区别?
URL 转 JSON 工具按需把单个页面变成结构化数据,无需配置。爬虫则是你自己写、自己托管、自己维护,用来持续抓取大量页面的代码。转换器适合一次性和小活,爬虫适合大规模的爬虫基础设施。
Q:把网页转成 JSON 合法吗?
从你有权访问的页面提取公开数据,通常没问题,但要看网站的服务条款和当地法律。避开登录后或付费墙内的内容,遵守 robots.txt 和频率限制,也别转发受版权保护的素材。
Q:把一个 URL 转成 JSON 要多久?
用免爬虫工具,单页通常两到五秒就能转好。没有环境要配置,所以从 URL 到可用的 JSON 几乎是即时的。
Q:什么时候该老老实实写爬虫?
当你需要按计划定时抓取成千上万的页面、要处理登录或强反爬、或者要深度爬遍整个站点时,就该写爬虫。比这更小的需求,URL 转 JSON 工具更快,而且没有维护成本。
结语 {#conclusion}
把网页数据提取成 JSON,已经不再等于写爬虫。先定好要的字段,选一个免代码的 URL 转 JSON 工具,粘进 URL,校验输出,再喂进工作流——每页通常不到一分钟。真爬虫留给真正的爬虫级任务;其余的,提取如今是随用随调的工具。Tabstack 的 Product Hunt 成绩,又一次说明"无需爬虫"正在成为日常网页数据处理的默认选项。
下一步:挑一个你一直想变成数据的页面,丢进转换器,亲眼看看那份 JSON。
需要把网页转成 JSON、Markdown、PDF 或其他格式?免费试用 URL to Any →——10+ 转换工具,无需注册,也没有爬虫要维护。