如何把网页内容喂给 ChatGPT:4 种有效方法
你在网上找到了一篇很有价值的文章,兴冲冲地粘贴到 ChatGPT 里提问,结果回答含糊不清,关键信息全丢了。问题出在哪?ChatGPT 并没有真正「读懂」那篇网页——它看到的只是一大段失去所有格式的文字碎片。
这篇指南介绍四种实用方法,让你把网页内容有效地喂给 ChatGPT。
目录
- 为什么 ChatGPT 处理不好原始网页内容
- 方法一:直接复制粘贴(快但有损)
- 方法二:先把 URL 转成 Markdown
- 方法三:使用 ChatGPT 自带的浏览功能
- 方法四:API + 预处理管道
- 提升效果的实用技巧
- 常见问题
为什么 ChatGPT 处理不好原始网页内容
从网页复制文本粘贴到 ChatGPT 时,你会丢失:
- 标题层级 — ChatGPT 分不清哪个是 H2,哪个是正文
- 列表和表格 — 全部变成连续的长段落
- 代码块 — 缩进和语法高亮消失
- 链接和引用 — 来源信息全部丢失
这很重要,因为 ChatGPT 依靠文档结构来理解上下文。一份格式良好的 Markdown 文档能清楚地告诉它什么是重点、什么是细节、各个段落之间是什么关系。
方法一:直接复制粘贴(快但有损)
最简单的办法:全选页面文字,复制,粘贴到 ChatGPT。
适用场景: 格式简单的短文——博客文章、新闻报道、纯文本页面。
不适用场景: 含代码块的技术文档、有表格的研究论文、或任何结构复杂的页面。
操作步骤:
- 打开目标网页
- Ctrl+A(Mac 用 Cmd+A)全选
- 复制后粘贴到 ChatGPT
- 在粘贴内容的上方或下方添加你的提问
缺点:你会把导航栏、页脚、Cookie 弹窗和侧边栏内容一起复制进去。ChatGPT 需要在这堆噪音中找到真正的文章内容。
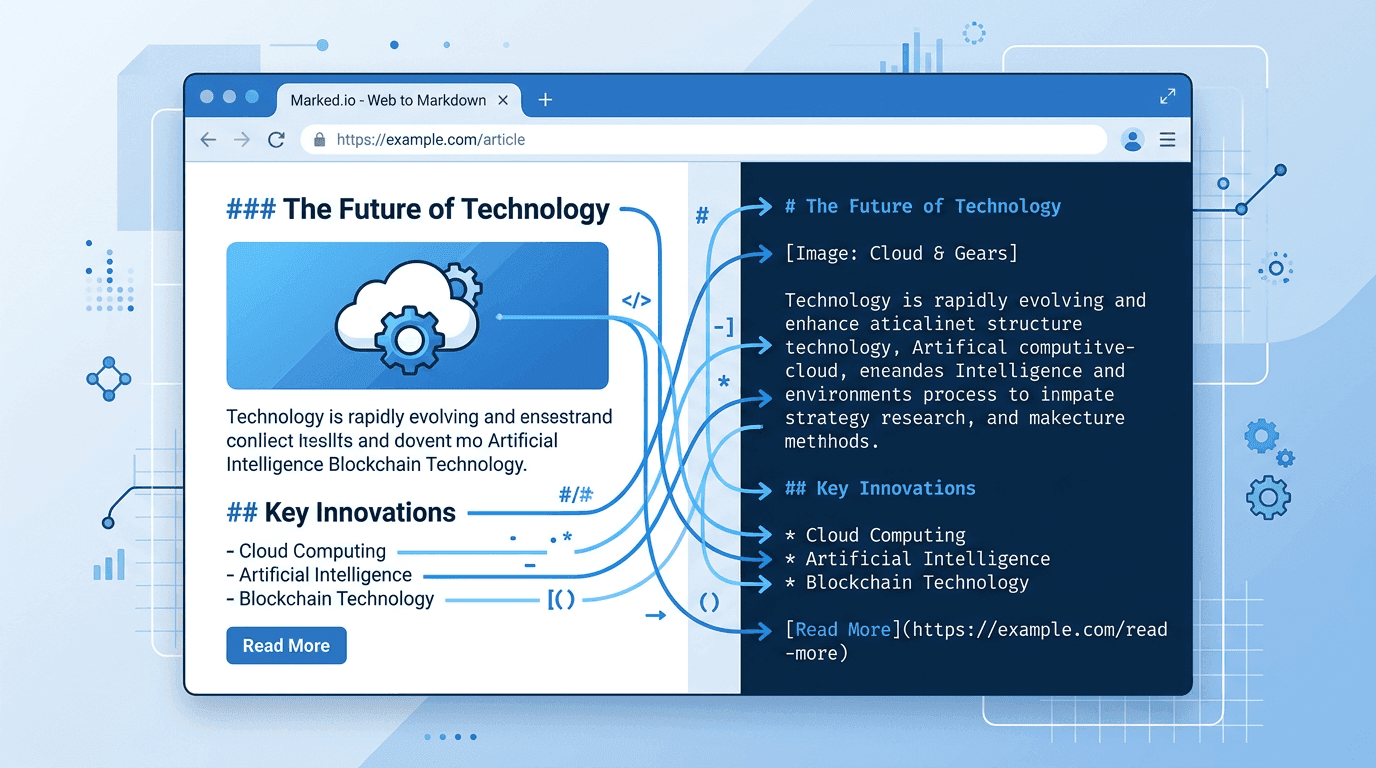
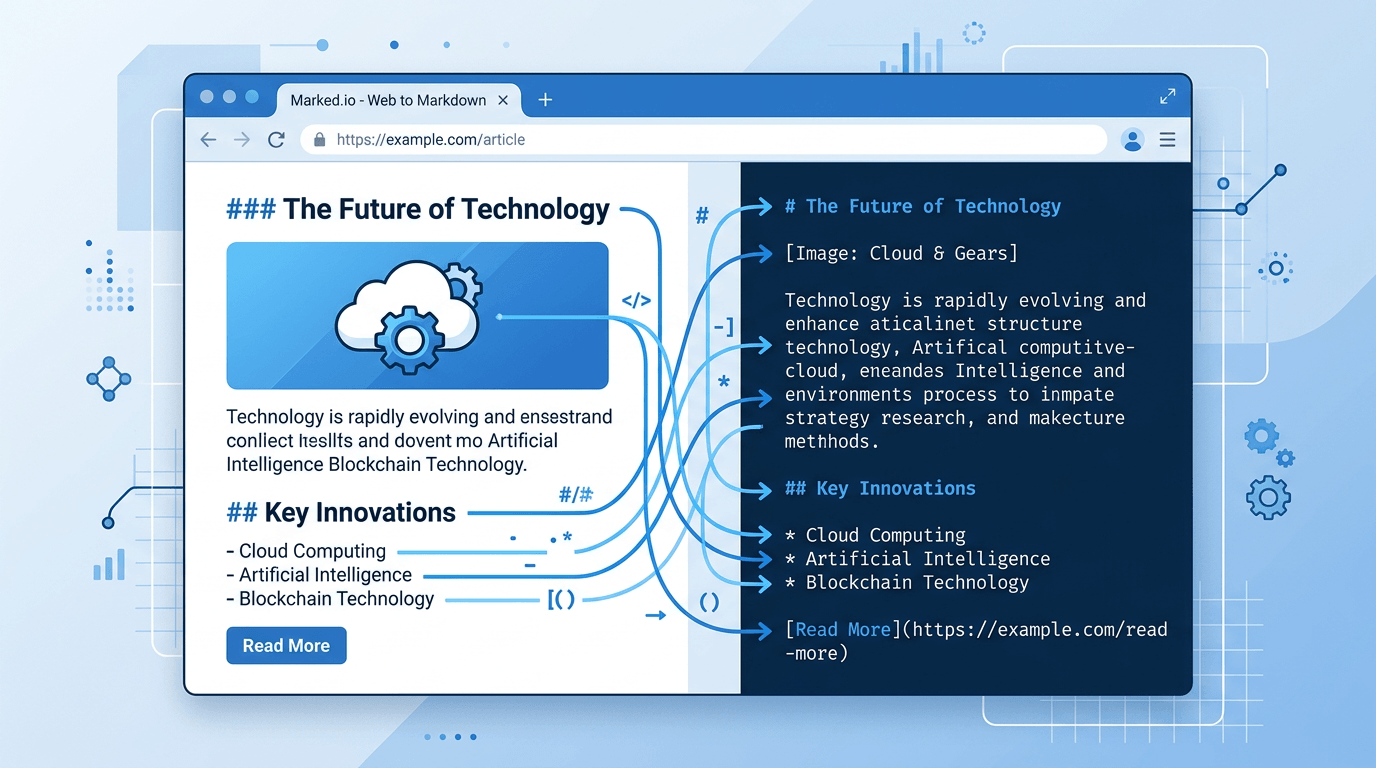
方法二:先把 URL 转成 Markdown
这是保留文档结构最可靠的方法。在发给 ChatGPT 之前,先把网页转换成 Markdown 格式。
Markdown 会完整保留标题、列表、表格、代码块和链接——这些正是 ChatGPT 理解内容所需要的结构信号。
操作步骤:
- 打开一个 URL 转 Markdown 的工具(比如 URL to Any,粘贴网址就能得到干净的 Markdown)
- 粘贴目标 URL
- 复制 Markdown 输出结果
- 连同你的提问一起粘贴到 ChatGPT
效果天差地别。ChatGPT 能看到文档结构,跟随逻辑脉络,在回答中引用具体的章节。

方法三:使用 ChatGPT 自带的浏览功能
ChatGPT Plus 和 Team 订阅用户可以让 ChatGPT 直接浏览 URL。
操作步骤:
- 输入:「阅读这篇文章并总结要点:[URL]」
- ChatGPT 会自动抓取并阅读页面内容
局限性:
- 仅限付费用户
- 部分网站会屏蔽 ChatGPT 的爬虫
- 付费墙或需要登录的内容无法读取
- 你无法控制 ChatGPT 提取了什么——它可能漏掉表格或代码
- 有频率限制:同一会话中频繁浏览会变慢
对于主流网站上的公开文章,这个方法够用了。但如果内容在付费墙后面或格式比较复杂,方法二更靠谱。
方法四:API + 预处理管道
面向开发者——当你需要在程序中批量处理网页内容时。
技术方案:
- 抓取 URL 并转换为 Markdown(使用爬虫 API 或 Readability 库)
- 清洗输出:去掉导航、广告和样板内容
- 将清洗后的 Markdown 作为 user message 发送给 ChatGPT API
import requests
import openai
# 第 1 步:将 URL 转换为 Markdown
response = requests.get("https://urltoany.com/api/function/to-markdown",
params={"url": "https://example.com/article"})
markdown_content = response.json()["content"]
# 第 2 步:发送给 ChatGPT
chat = openai.ChatCompletion.create(
model="gpt-4",
messages=[{
"role": "user",
"content": f"总结这篇文章:\n\n{markdown_content}"
}]
)
print(chat.choices[0].message.content)
这种方式可以扩展到处理数百个页面,而且你能完全控制 ChatGPT 看到的内容。
提升效果的实用技巧
- 告诉 ChatGPT 输入格式。 在提问开头写明 "以下是来自 [URL] 的 Markdown 文档:",让它知道该如何解读。
- 长文章分段处理。 如果页面超过 ChatGPT 的上下文窗口,按章节标题拆分,逐段处理。
- 保留标题。 不要删除 Markdown 中的 H2/H3 标记——它们是模型最有用的结构信号。
- 附上原始 URL。 虽然 ChatGPT 无法访问,但来源 URL 有助于它给出更准确的回答。
- 提问要具体。 "作者在第三节的核心论点是什么?" 远比 "说说这篇文章" 效果好。

常见问题
Q:直接粘贴 URL,ChatGPT 能读取网页吗?
不能。免费版 ChatGPT 无法访问 URL,它只会看到链接文本本身(如 "https://example.com"),而不是页面内容。你需要使用浏览功能(付费版)或手动粘贴页面内容。
Q:喂给 ChatGPT 的最佳格式是什么?
Markdown。它能保留标题、列表、表格和代码块,同时保持轻量。ChatGPT 处理 Markdown 的效果比原始 HTML 或纯文本好得多,因为结构标记(##、-、|)清晰且无歧义。
Q:ChatGPT 一次能处理多少网页内容?
GPT-4 Turbo 支持最多 128K token(大约 10 万个英文单词)。大多数网页文章都能轻松放下。如果页面特别长,按章节拆分逐段处理即可。
Q:输入内容越长,ChatGPT 的准确性会下降吗?
会有一定影响。研究表明,大语言模型对长输入中间部分的内容关注度较低("迷失在中间" 效应)。保持输入结构清晰、标题明确,有助于缓解这个问题。
Q:有没有办法自动化地把网页喂给 ChatGPT?
有。使用 API 方案(方法四):通过爬虫服务将 URL 转为 Markdown,然后发送给 ChatGPT API。可以设置定时任务或按需触发。
总结
"粘贴 URL" 和 "ChatGPT 真正理解页面" 之间的差距,归根结底在于格式。先把网页转成 Markdown,你会得到能引用具体章节、跟随逻辑结构、捕捉细节的高质量回答。
日常使用推荐方法二,操作简单效果好。如果你在做需要批量处理网页内容的产品,值得花时间搭建方法四的管道。