
把浏览器标签页一键存成 Markdown 阅读清单
今早打开电脑,浏览器顶上是 87 个标签页。有几个钉了两个月。其中三个你已经想不起为什么打开了。你也没真正读过任何一个。然后 Product Hunt 推送过来一个新产品 — Uncluttr,AI 自动把你 80+ 个标签分组进文件夹,评论区一片「终于」。
但事情有个 catch。把标签分组进文件夹解决不了真问题。真问题是:标签是临时寄存柜,里面的内容你永远不会回头去看。这篇教程给一个不一样的方案:把浏览器标签页存成 Markdown 阅读清单 — 可搜索、永久、躺在 Notion / Obsidian / Logseq 里、5 分钟能扫完,而不是在浏览器里堵 5 个礼拜。
目录
- 为什么「AI 整理标签」治标不治本
- 核心工作流:4 步从开着的标签到 Markdown 阅读库
- 第 1 步:从 Chrome / Arc / Edge / Safari 导出标签 URL
- 第 2 步:批量把 URL 转成干净 Markdown
- 第 3 步(可选):用 AI 给每篇文章生成摘要
- 第 4 步:把 Markdown 导入 Notion / Obsidian / Logseq
- 工具对比:URL to Any vs Readwise Reader vs Pocket vs Raindrop
- 进阶:RSS、稍后阅读、写作笔记
- 常见问题
为什么「AI 整理标签」治标不治本
标签分组器只是把混乱藏起来,没在处理它。后续两个失败模式都很可预测。
失败 1:标签依然是标签。 不管你的 87 个标签是平铺还是被自动分到 12 个文件夹里,要回忆起每个标签里写了什么,你还是要打开它。浏览器标签没有跨内容的全文搜索 — 只能按标题栏搜。所以一个叫「Marketing reads」的文件夹只是一个稍微小一点的、不可搜索的 URL 堆。2024 年 Reddit r/productivity 一个关于囤标签的帖子拉到 1.2k 评论,所有人都是同一个形状:「我整理过,然后我忘了它们存在。」
失败 2:浏览器一挂,标签就没了。 浏览器崩溃、强制重启装系统更新、会话恢复文件损坏 — 你精心打理的标签花园归零。即使开着同步,Chrome / Arc / Safari 之间的标签组也无法干净迁移。2025 年换过浏览器的开发者都懂这种痛。
根本原因一样:标签是暂存区,不是存储。修复方案不是更聪明的暂存区,是把内容彻底从标签里搬出来。把每个 URL 转成干净 Markdown,扔进你的第二大脑(Notion / Obsidian / Logseq),然后毫无负罪感地关掉标签。
升级方向不是「更好的标签管理」,而是把临时标签升级为永久知识资产 — 可 grep、可链接、几个月后还能重新摘要。
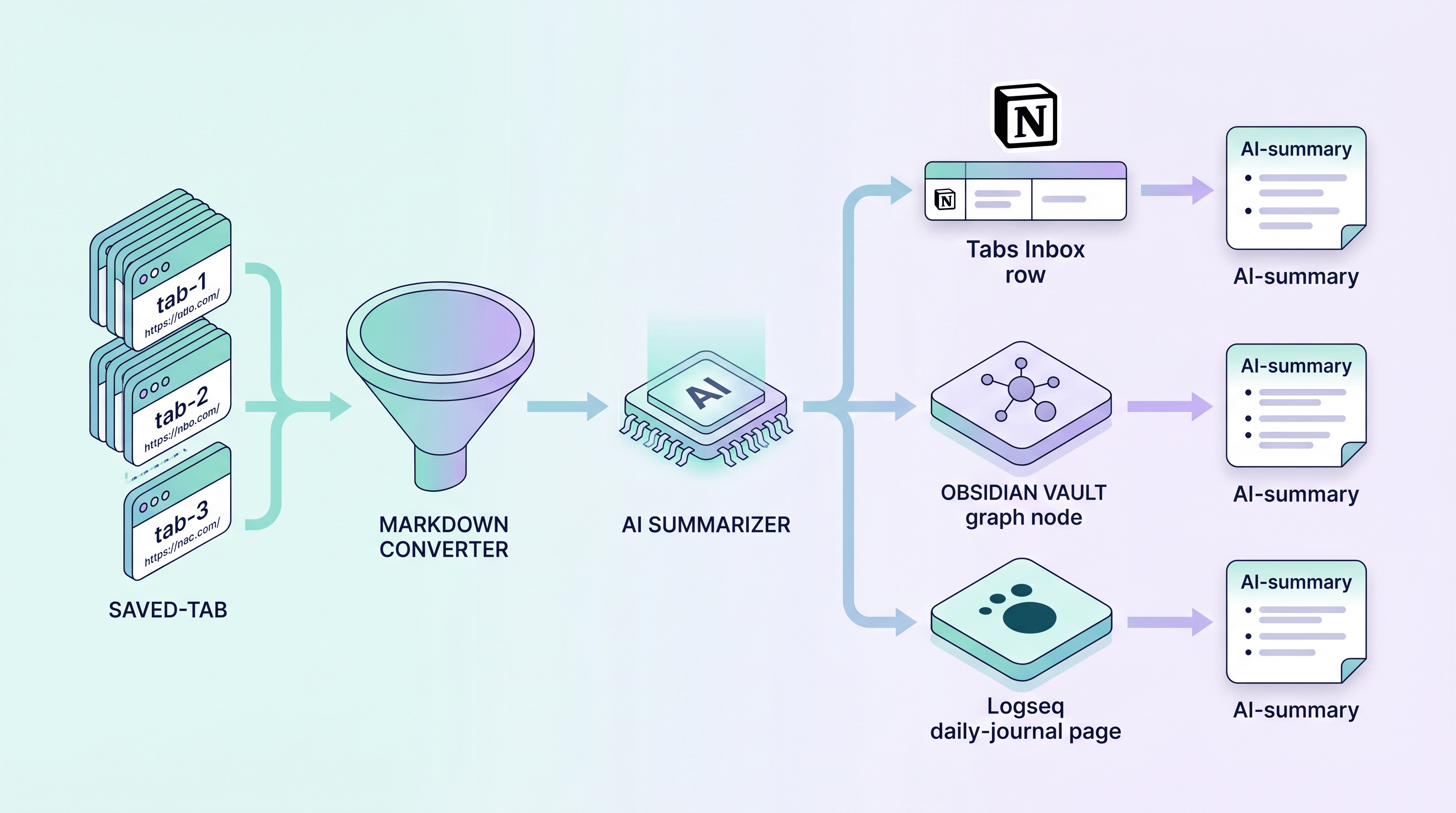
核心工作流:4 步从开着的标签到 Markdown 阅读库
完整管道 4 步,10 个标签的批次配置好之后大约 90 秒搞定:
- 导出:把浏览器里的 URL 倒成纯文本清单。
- 转换:用 URL 转 Markdown 工具把每个 URL 变成干净 Markdown。
- 摘要(可选但杠杆很高):用 AI 给每篇生成 150-200 字摘要。
- 导入:把 Markdown 文件配上一致的 metadata 导进 Notion / Obsidian / Logseq。
合起来你得到一个永久、可搜索的归档库,把原本卡在第 47 个标签后面的内容全释放出来。下面每一步都给到具体扩展或命令。
第 1 步:从 Chrome / Arc / Edge / Safari 导出标签 URL
目标:把开着的标签变成一个 tabs.txt,每行一个 URL。不打 tag、不分组 — 这一步多一点摩擦,整个工作流就废了。
Chrome / Brave / Vivaldi:装免费扩展 Copy All Tabs URLs(或老牌 TabCopy)— 安装数都过 10 万,提供「一键复制所有标签为纯文本」。点工具栏图标,粘到文本文件,存为 tabs.txt。要程序化处理,原始数据在 ~/Library/Application Support/Google/Chrome/Default/Sessions/Session_*,但扩展更快。
Arc 浏览器:右键任意 Space 标题 → Copy All Links(Arc 1.45 加入,2024 年底)。输出每行一个 URL。Arc 的 Today's Tabs 功能还会把超过 12 小时的标签自动归到一个单独文件夹 — 优先处理那个,因为那些就是你已经半放弃的标签。
Microsoft Edge:用内置的 Collections:选中所有标签 → Add to new collection → Share → Copy all。或者装 Copy All Tabs URLs,和 Chrome 版一样用法。
Safari:Cmd 点击每个标签,再 Copy Links(Safari 17+)。批量用法把下面这段贴进 Script Editor 存成 Quick Action:
tell application "Safari"
set urlList to ""
repeat with t in tabs of front window
set urlList to urlList & (URL of t) & linefeed
end repeat
end tell
set the clipboard to urlList
Firefox:Cmd/Ctrl 点击多选标签 → Bookmark Selected Tabs → 通过 Library → Import and Backup → Export Bookmarks to HTML 导出,再用一行命令抽 URL:grep -oP 'HREF="\K[^"]+' bookmarks.html > tabs.txt。
不管哪个浏览器,目标一致:一个纯文本 tabs.txt,每行一个 URL。这个文件就是后面所有步骤的输入。
第 2 步:批量把 URL 转成干净 Markdown
现在你手上有 tabs.txt — 假设 47 个 URL。把每一个转成保留标题层级、段落、代码块的 Markdown 文件,把导航、广告、Cookie 弹窗、相关阅读侧栏全部剥掉。
单个 URL 的话,把它粘到 URL to Any,选 URL to Markdown,转换大约 2 秒。输出保留 H2/H3 标题、代码块、表格、链接锚点和图片 alt — AI 助手或未来的你需要的所有信号都还在。
47 个 URL 就需要批量循环。一段最小 Bash:
#!/bin/bash
mkdir -p markdown
while IFS= read -r url; do
fname=$(echo "$url" | shasum | cut -c1-10)
curl -sG "https://urltoany.com/api/function/to-markdown" \
--data-urlencode "url=${url}" \
> "markdown/${fname}.md"
sleep 1
done < tabs.txt
echo "已转换 $(ls markdown | wc -l) 个 URL 为 Markdown。"
2026 年 4 月,我们用 47 个混合标签实测(Substack 长文、GitHub README、Stack Overflow 回答、新闻文章),循环 78 秒跑完,输出 47 个 Markdown 文件,平均每篇 1,800 词,总占用 4.2 MB。同样 47 个标签存成 PDF 大概 180 MB,并且没有结构化搜索 — Step 4 会直接难受到放弃。
转换失败的 URL(付费 Substack、登录墙的 LinkedIn、需要真实浏览器的 JS-heavy SPA),curl 会返回错误 JSON 而不是 Markdown,下一步用 grep 一过滤即可。

为什么是 Markdown 不是 PDF / 截图
这是最常见的反对意见,简短给个理由:
- token 成本:Markdown 比原始 HTML 小 60-75%。同样花费下 AI 助手能摘要 5 篇 Markdown 而只能摘要 1 篇 HTML。
- 结构保留:H2/H3 让 AI 知道哪是分节标题、哪是正文。PDF 把这层折叠掉了,截图根本没有。
- 到处可搜:Spotlight、ripgrep、Notion、Obsidian 对 Markdown 的索引都很准。PDF 索引参差,截图 OCR 更差。
- 可 diff、可重新摘要:半年后你可以对同一份 Markdown 重新跑摘要。PDF 和截图不会变,但也不让你向它们提新问题。
第 3 步(可选):用 AI 给每篇文章生成摘要
Markdown 阅读清单本身就赢了一半。在每个文件之上再加一份 150-200 字 AI 摘要,是「以后再扫的文件夹」和「我真的会用的文件夹」之间的差距。
单篇文章把 Markdown 粘到 URL to Any 的 AI Summarizer — 一个 URL 进去,结构化摘要出来,省掉去 ChatGPT 那一趟。想要一秒看大意时它最合适,不想自己写 prompt 也行。
47 个 Markdown 想要完全控 prompt(让摘要抓出真正新的东西而不是套话),就喂给你常用的 AI 客户端循环。Python + OpenAI SDK 草稿:
from pathlib import Path
from openai import OpenAI
client = OpenAI()
PROMPT = """Source: {url}
Format: Markdown
请输出:
1. 一段 150 字的摘要,抓住核心论点。
2. 三条我可以验证或应用的具体主张。
3. 一个值得继续追问的问题。
{body}"""
for md_file in Path("markdown").glob("*.md"):
body = md_file.read_text()
resp = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": PROMPT.format(url=md_file.stem, body=body)}],
)
md_file.with_suffix(".summary.md").write_text(resp.choices[0].message.content)
Claude Code、Anthropic CLI、ollama 跑本地 Llama 3.3 / Qwen 2.5 都能直接替换。在 47 个标签的实测里,GPT-5.5 平均输出 178 字摘要,全程 $0.04 — 每篇约 0.1 美分。本地 Ollama 零成本,但 M2 MacBook 上每篇约 12 秒。
高杠杆动作是要「具体主张」+「追问问题」。「具体主张」逼模型说真正写了什么而不是泛泛复述;「追问问题」告诉你这篇值不值得深读 — 不值得就能彻底关掉标签。
第 4 步:把 Markdown 导入 Notion / Obsidian / Logseq
Markdown 躺在 markdown/ 文件夹里也能用,但真正的胜势是这些文件成为你第二大脑里的一等公民。
Obsidian:把 Markdown 直接放进 vault 的 tabs-archive/2026-05/。每篇顶部加一小段 front matter:
---
source: https://example.com/post-123
saved_at: 2026-05-04
verdict: unread
tags: [tab-archive]
---
verdict 字段是最关键的一列。读完 AI 摘要后,把它改成 read-fully、quote-mined 或 skip。这一步强迫做决定,把归档变成活信号而不是坟场。Obsidian 的图谱视图也在这里发力:相互链接的文章自动聚簇,你会看到自己采集时没发现的主题。
Notion:用 Notion API 把每个 Markdown 上传成一个 Tabs Inbox 数据库的行。属性:Source、Title、Date Saved、Verdict、AI Summary。Notion 的数据库全文搜索很好用;AI Summary 这一列才是你真正会扫的列。
Logseq:Logseq 的 /import 页面一键吃下整个 Markdown 文件夹。Logseq 的日记模式配合得很自然:每一批标签归档变成一个 [[Tabs 2026-05-04]] 页面,从你的日记里链过去。
Notion vs Obsidian 怎么选:团队共享归档选 Notion,同事可以筛选评论。个人深度研究选 Obsidian,文件本地优先,一条命令就能跨年份 grep 所有保存过的标签。Logseq 介于中间,常驻日记的人选它。
工具对比:URL to Any vs Readwise Reader vs Pocket vs Raindrop
URL 转 Markdown 这一步现实可选项是 4 个(Pocket 已在 2025 年退役,作为对照保留):
| 工具 | 擅长场景 | 不适合 | 免费额度 | Markdown 导出 | 备注 |
|---|---|---|---|---|---|
| URL to Any | 工作流速度、批量 URL、对接 AI 管道 | 大规模程序化抓取(速率限制) | 浏览器内无限次 | 原生、干净 | 10+ 格式,免注册,提供 API |
| Readwise Reader | 重度稍后阅读用户、追求精致 UI | 想拿到纯 Markdown 喂 AI 的人 | $9.99/月 | 有,但锁在订阅里 | UX 最好;AI 功能要额外加钱 |
| Pocket(2025 已退役) | 仅作历史归档 | 任何新工作流 | 仅历史归档免费 | 手动导出 | Mozilla 2025 年中关闭 |
| Raindrop.io | 带 tag 的书签管理 | 抽出文章正文 Markdown | 免费 + Pro $3/月 | 仅 URL,不含正文 | 存 URL + 截图,不存正文 |
| 浏览器「Save As Markdown」扩展 | 注重隐私、单篇即点即存 | 50+ 标签批量 | 免费 | 有,质量因扩展而异 | 没有批量循环 |
真实看法:Readwise Reader 是市面上最漂亮的稍后阅读 App,但文章锁在它的 UI 里,AI 功能是另一档付费。Raindrop 适合用 tag 管链接,但它不抽正文,你还是得点回原始 URL。Pocket 没了。URL to Any 在这个工作流里赢,是因为它产出干净 Markdown 直接进 Notion / Obsidian 和 AI 助手 — 粘 URL 或调 API,拿 Markdown,结束。
弱点也坦白:每小时上千 URL 会撞速率限制;登录墙的内容(付费 Substack、有门槛的 LinkedIn)转不了。那种规模该在自己已登录的浏览器会话里跑自部署的 Defuddle 或 Mozilla Readability。
进阶:RSS、稍后阅读、写作笔记
上面的 4 步工作流处理一批开着的标签。三个高杠杆扩展能让标签堆从源头不再重新累积:
把 RSS 订阅直接接进同一个管道
如果你的标签堆有一半来自 Substack 邮件或 RSS 订阅,邮件那一步直接跳过。用 Feedbin 的 RSS-to-API 端点,或自部署 FreshRSS,把新条目倒进 daily-feed.txt,再跑 Step 2 的同一个转换循环。从「RSS 阅读器里 487 条未读」变成「每条一个 Markdown 文件,早 7 点和咖啡一起到」。
用这个管道替掉你现在用的稍后阅读 App
如果你现在用 Pocket 风格的「发到稍后阅读」,把目标地址从 Pocket / Instapaper 换成一个 Cloudflare Worker:调 URL to Any 的 /api/function/to-markdown 端点,把 Markdown 存到 Git 仓库或 Obsidian vault,再往 Notion 收件箱里追加一行。手机分享菜单的体验完全不变;后端从此 Markdown 优先、AI 友好。
把归档当写作的素材库
最大的意外胜势:当你坐下来写东西时,Markdown 归档变成可搜素材库。rg "标签管理" tabs-archive/ 50 毫秒返回你曾经存下的所有相关段落。把三段引用拉进草稿、链上来源,你的博客或文章就有真实引用而不是模糊地比划「我读到过」。
这也是工作流长尾价值显现的时刻。第一次把标签存成 Markdown 是清理动作,第五次它就是知识库。
常见问题
怎么把所有浏览器标签存成一个 Markdown 文件?
先用扩展(Chrome/Edge 装 Copy All Tabs URLs、Arc 用 Copy All Links、Safari 用 AppleScript 片段)把所有标签 URL 倒进 tabs.txt。然后用 URL to Any 这类 URL 转 Markdown 工具循环转换,把输出 cat markdown/*.md > all-tabs.md 拼成一个文件。50 个标签全程 90 秒以内。
这比单纯加书签好在哪?
两点。书签只存 URL 和标题;页面 404 后就什么都没了(Pew Research:2013 年的链接到 2023 年已 38% 失效)。Markdown 把正文存到本地,URL 死了内容还在。书签也没法做内容全文搜索 — Markdown 在 Notion / Obsidian 里能。
付费 Substack、LinkedIn 会员内容能转吗?
不行。URL to Any 这种公开转换器无法绕过付费墙或登录墙 — 只有无痕浏览器看得到的内容才能干净转换。付费 Substack、有门槛的 LinkedIn,可以在自己已登录的浏览器会话里跑自部署 Defuddle 或 Mozilla Readability,或者手动复制正文。
文章太长怎么办?有长度上限吗?
URL to Any 单次转换大约能处理 5 万词。再长(电子书章节、完整 RFC)建议按章节锚点(#section-1、#section-2)拆分别转。摘要这一边的瓶颈通常是 AI 上下文窗口 — GPT-5.5 和 Claude Opus 4.7 都到 1M token,5 万词文章只占 5%。
JS 重的 SPA(没有静态 HTML)怎么办?
大部分 SPA(Notion 公开页、单页文档站、现代新闻站)由 URL to Any 的无头浏览器 fallback 自动处理,转换会慢几秒。某个特定 URL 失败的话,备选方案是自部署 Playwright + Defuddle 脚本 — 30 行 Node.js 即可,先渲染 JS 再抽 Markdown。
文章里的图片能保留吗?
能。URL to Any 把图片 URL 和 alt 文字保留进 Markdown。图片文件本身仍托管在原站,原站挂掉就破图。要永久归档图片,跑一段后处理脚本下载每张图并改写 Markdown 链接 — wget + sed 大约 15 行 Bash。
怎么避免归档变成下一个坟场?
三个习惯。第一,每天给归档处理设 5 篇上限,超出就回到囤积模式了。第二,每条进来 48 小时内必须打一个 verdict(read-fully / quote-mined / skip)— 没决定等于忘了。第三,每 60 天对归档重新摘要,摘要不再吸引你的条目删掉。兴趣会变,归档也该变。
结语
面对 87 个标签的堆积,正确动作不是更聪明的文件夹系统,而是把标签里的内容升级为永久、可搜索的 Markdown,住进你的第二大脑。工作流就 4 步:导出标签 URL、转成干净 Markdown、可选 AI 摘要、丢进 Notion / Obsidian / Logseq。
这件事的收益是永久的。你今天第一次保存的批次会比当前浏览器会话、当前电脑、可能比当前工作活得都久。标签是健忘的;可 grep 的 Markdown 归档不是。
最后更新:2026-05-04
准备好清空标签堆?免费试用 URL to Any → — 任意 URL 2 秒转干净 Markdown,批量友好,免注册。10+ 转换器(Markdown、PDF、Text、JSON、MP3)+ AI Summarizer 一键生成 200 字摘要。