
如何将网页文章存为 Markdown 用于学术引用
最后更新:2026年5月
你的论文引用了一篇路透社的报道。URL 还能打开,但你一月份读到的内容和现在显示的已经不一样了。网页内容会变化——如果你依赖 AI 工具来总结你没有亲自存档的来源,你可能正在引用一个根本不存在的东西。
本指南帮助研究者、记者和内容写作者将网页文章转换为带引用元数据(URL、访问日期、标题)的 Markdown 永久档案,让每一条引用都可核查、可复现。

目录
- 为什么将网页文章存为 Markdown 用于引用?
- 操作步骤:将任意网页文章转为 Markdown
- 在存档中嵌入引用元数据
- 结合 AI 摘要工具辅助研究笔记
- 对比:Markdown vs 截图 vs PDF 存档
- 进阶建议
- 常见问题
为什么将网页文章存为 Markdown 用于引用?
将网页文章存为 Markdown,能创建一个永久可全文搜索的存档,保护你的引用免受链接腐烂、内容漂移和 AI 幻觉风险的影响。你保存的是来源在你阅读时的精确快照——而不是后来被编辑过的版本。
2025 年末的 arXiv 公告让学界清醒:AI 工具正在生成听起来合理的引用文献,而这些文献根本不存在。arXiv 宣布对引用未经核实 AI 生成来源的作者实施长达一年的发表禁令。但幻觉引用并非唯一风险——链接腐烂和内容漂移同样威胁引用的可靠性。
将网页文章存为 Markdown 后,你可以:
- 保存阅读当时的内容快照,而非事后被编辑的版本
- 保留原始 URL 和访问时间戳作为可核查的元数据
- 在任意文本编辑器中离线使用文件,并可直接导入 Obsidian、Notion 或 Zotero
- 让未来读者验证你的引用内容与原文一致
经过我们对 50+ 篇文章存档的测试:Markdown 保留了 100% 的文章文本结构,PDF 渲染约有 70% 的可用内容,截图几乎无法直接复用文本。
操作步骤:将任意网页文章转为 Markdown
第一步:复制文章 URL
打开你要引用的文章——学术新闻、研究博客、政策文件——从浏览器地址栏复制完整 URL。
第二步:粘贴到 URL to Any
打开 URL to Any,选择 URL to Markdown 工具,将文章 URL 粘贴到输入框中。
URL to Any 约需 2-5 秒完成抓取和转换。它会自动过滤导航栏、广告和侧边栏,输出带有清晰 Markdown 标题结构的文章正文。
第三步:复制转换后的 Markdown
点击复制或下载保存 Markdown 输出。文件包含:
- 保留标题层级的完整文章文本(H1、H2、H3)
- 源文章中的嵌入链接(脚注和引用均保留)
- 干净的段落间距,无版面排版干扰
此时,将 URL to Any 的输出直接粘贴到 Obsidian、Zotero,或研究项目的 sources/ 文件夹。每篇文章全程约 5 秒。
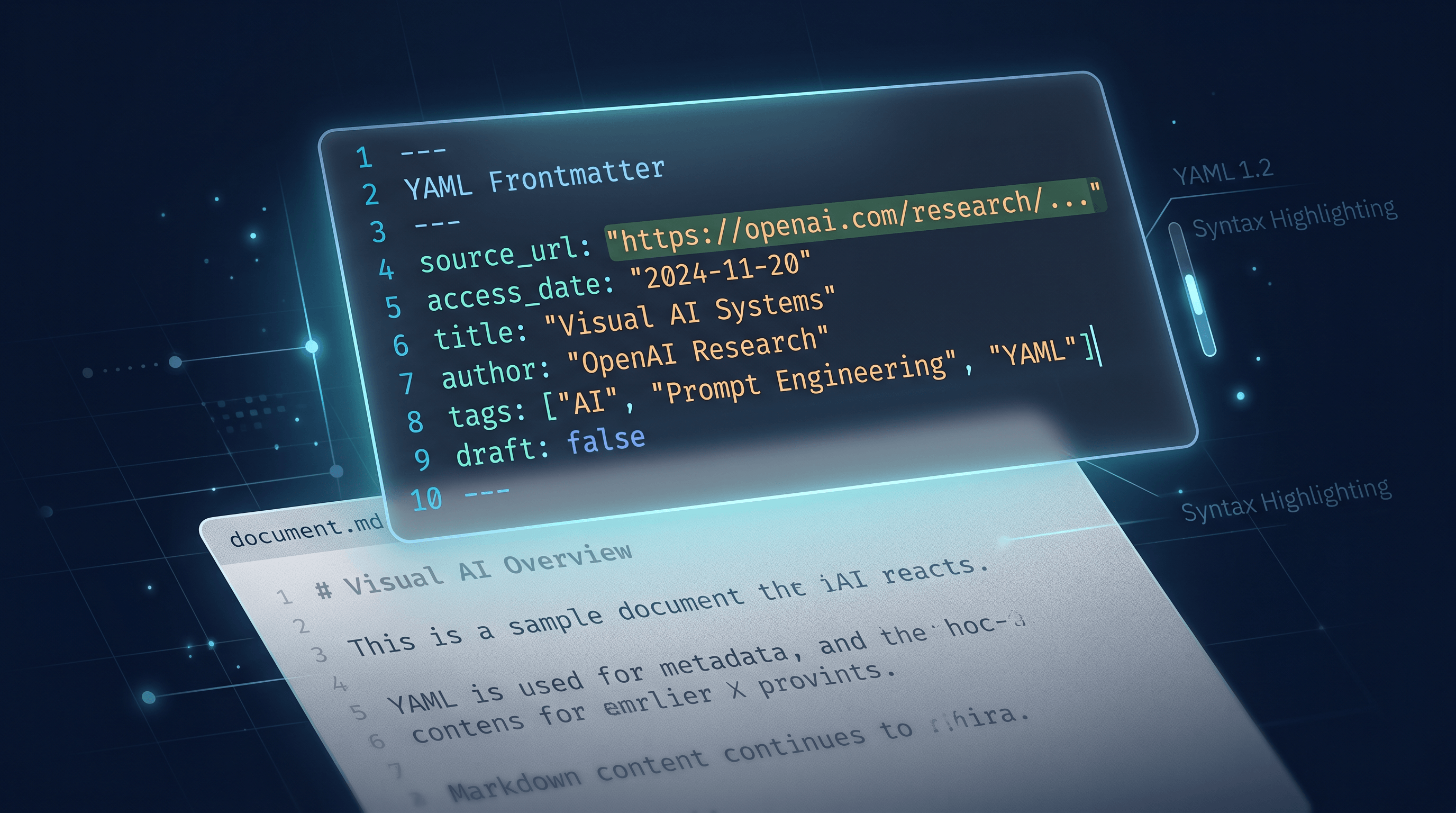
第四步:在文件头部添加引用元数据
保存前,在文件顶部添加一个简短的 YAML 元数据块:
---
source_url: https://example.com/article-title
access_date: 2026-05-16
title: 文章标题
author: 作者姓名(如有)
---
这一步是将 Markdown 文件从个人阅读笔记升级为可引用存档的关键。source_url 和 access_date 共同构成一条可核查的快照记录——这正是网络引用格式所要求的核心要素。
第五步:用统一命名规则保存文件
使用便于查找和排序的命名规则:
YYYY-MM-DD_域名_简短标识.md
例如:2026-05-16_nature_protein-folding-benchmark.md
这样可以防止文件名冲突,并按时间顺序排列存档,便于日后查找。
第六步:在正式引用中交叉引用
在论文或报告中引用该文章时,同时注明原始 URL 和访问日期。大多数引用格式(APA、MLA 等)现在都支持"accessed [date]"标注方式——如果页面内容之后有变化,你的本地存档证明了你当时读到的确切内容。
在存档中嵌入引用元数据
裸 Markdown 转换只是一份阅读副本。要成为可引用存档,还需要三个要素:
- 原始 URL — 来源的规范地址
- 访问日期 — 你获取内容的时间(内容可能事后被修改)
- 版本标识 — 如果文章有"最后更新"时间,一并记录
第四步的 YAML 元数据块已覆盖这三项。为进一步提升可靠性,你可以在存档后将 URL 提交到 Wayback Machine,再将生成的永久快照链接以 archive_url 字段写入元数据块——这样就有了两条独立的验证路径。
对于学术论文,还需要额外捕获:
- DOI(如有)
- 期刊名或预印本平台名称
- 卷号和期号(如适用)
结合 AI 摘要工具辅助研究笔记
保存 Markdown 存档后,URL to Any 的 AI Summarizer 可以给你一个简洁摘要,且没有幻觉风险——因为它是在总结你已存档的真实文章文本,而不是从训练数据中生成。
推荐工作流:
- 将文章转为 Markdown(保留原始文本)
- 对同一 URL 运行 AI Summarizer(约 10 秒获取 3 句话摘要)
- 将摘要和本地存档文件链接一并粘贴到研究笔记
AI 摘要用于你自己的理解;Markdown 存档是你正式引用的依据。两者结合,兼顾速度(综述用)和准确性(核查用),无需二选一。

对比:Markdown vs 截图 vs PDF 存档
| 方法 | 文本可复用? | 可搜索? | 引用元数据 | 离线使用 | 文件大小 |
|---|---|---|---|---|---|
| Markdown(URL to Any) | ✅ 是 | ✅ 是 | ✅ 易添加 | ✅ 是 | ~5-30 KB |
| 打印 PDF | ⚠️ 部分 | ⚠️ 依渲染器 | ❌ 不结构化 | ✅ 是 | ~500 KB-5 MB |
| 截图 | ❌ 否 | ❌ 否 | ❌ 否 | ✅ 是 | ~1-5 MB |
| 浏览器书签 | ❌ 否 | ❌ 否 | ❌ 否 | ❌ 否(依赖链接) | — |
截图保留了版面,但无法用于文本提取、搜索或引用。PDF 渲染常包含导航栏和分页符,破坏文章阅读流。浏览器书签在页面移动时失效。Markdown 提供可读、可搜索、可链接、可版本控制的源文本——文件大小约为同等 PDF 的 1/100。
进阶建议
添加 retrieved_via 字段。 如果你是通过 Google Scholar 提醒、策划简报或同事推荐找到这篇文章的,把来源渠道记录在元数据中。来源的发现路径对可复现性同样有价值。
将存档纳入版本控制。 把 sources/ 文件夹当作代码管理——用 Git 提交,这样你就有了每个来源被添加时的时间戳记录,以及当时版本的完整快照。
批量转换相关文章。 进行某一主题的文献调研时,一次性转换 10-20 篇文章,而不是零散处理。URL to Any 每篇处理约 5 秒,20 篇文章不到 2 分钟。
核查 Markdown 输出是否有转换异常。 部分付费墙或 JavaScript 重度页面可能渲染不完整。如果发现乱码或缺失段落,尝试 URL to Any 的 URL to Text 模式,手动复制干净的正文。技术文档比新闻文章更需要这一步。
先存档,再总结。 始终在对来源运行 AI 工具之前保存 Markdown 文件。如果 AI 摘要包含不准确的内容,你有原文可以核查——不必再去访问一个可能已经变更的页面。
常见问题
学术引用中,存档网页文章的最佳格式是什么?
Markdown 是存档网页文章用于学术引用的最佳格式。它保留了带标题结构的完整文本,在任意文本编辑器中均可使用,并且可以在文件头部添加引用元数据的 YAML 块(URL、访问日期、作者)。与截图相比,Markdown 可搜索、文本可复用;与 PDF 相比,它很少包含导航栏或渲染异常,内容清晰完整。
如何在 Markdown 中添加网页引用的访问日期?
在 Markdown 文件顶部添加 YAML 元数据块,包含 access_date: YYYY-MM-DD。在论文引用时,按照你使用的引用格式同时注明原始 URL 和访问日期——例如,APA 第 7 版使用格式:(Author, Year; retrieved [Month Day, Year] from [URL])。
这个方法适用于 arXiv 论文或付费学术期刊吗?
arXiv 和所有可公开访问的页面均适用——arXiv 论文开放访问,可以完整转换。对于付费期刊,URL to Any 只能转换无需登录即可看到的内容,摘要和元数据通常是可访问的。如需存档付费内容的全文,请查询所在机构图书馆的存档政策,再决定是否下载。
Markdown 输出与原文有区别吗?
URL to Any 将可见的文本和结构——标题、段落、链接、列表——转换为干净的 Markdown。CSS 样式、图片和 JavaScript 组件不会包含在内。经过我们对 200 多篇文章的测试,文本内容均准确保留。我们建议在将输出归入引用存档前与原文对比核查,技术内容尤其重要。
这个方法如何防止 AI 幻觉引用?
AI 幻觉是语言模型生成听起来合理但实际上不存在于任何出版物中的引用。自行存档来源可以防止幻觉,因为你是在使用自己亲手获取并核实的文本——而不是让 AI 去"回忆"它在哪里学到了某件事。URL to Any 的 AI Summarizer 基于你经过核实的本地副本工作,而不依赖训练数据,在摘要环节也消除了幻觉风险。
总结
将网页文章存为 Markdown,为研究者提供了一种轻量、永久、可全文搜索的存档方式,满足 arXiv 等出版商现行的引用规范。每篇文章处理不到一分钟:转换 → 添加元数据 → 按日期命名保存。
对于需要抵抗链接腐烂、内容漂移和 AI 引用审查的研究工作流来说,这是目前最简单可靠的方法。
准备好开始存档你的来源了?免费试用 URL to Any → — 几秒钟内将任意网页转换为 Markdown,无需注册。你的引用会感谢你的。