
网页转 NotebookLM 知识源:5 步完整工作流
最后更新:2026 年 5 月
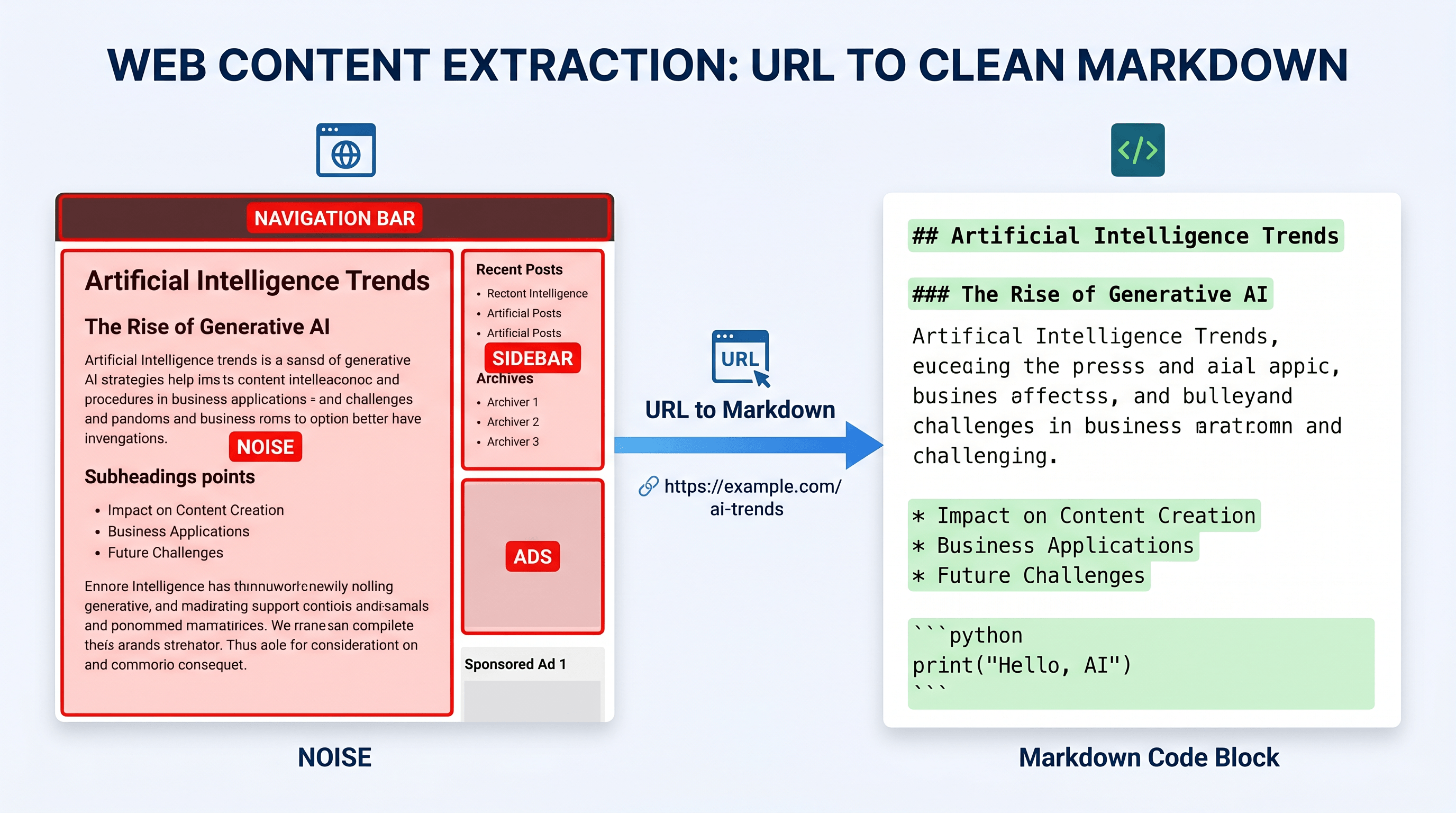
NotebookLM 支持上传文档作为知识来源,但要把网页内容干净地导入进去,比想象中更麻烦。官方 URL 导入会抓取整个页面,包括导航栏、广告、侧边栏和 Cookie 提示——真正有用的文章正文反而被这些噪音淹没。本文介绍一个 5 步工作流:用 URL to Any 把任意网页提取为干净的 Markdown,再作为高质量知识源导入 NotebookLM。

目录
挑战:NotebookLM 官方 URL 导入的局限 {#challenge}
NotebookLM 支持直接添加网页 URL 作为知识来源,但实际效果参差不齐。当你粘贴 URL 时,NotebookLM 会爬取整个页面,连同导航菜单、Cookie 弹窗、侧边栏和页脚链接一起抓取——真正有用的文章内容只是其中一部分,AI 需要在大量噪音中识别有效信息。
研究人员收集 20 篇博文做文献综述,或产品经理搭建竞品情报库,都会遇到同样的摩擦:知识源的质量完全取决于抓取到的页面有多干净。对于重度依赖 JavaScript 渲染的页面——单页应用、动态加载内容——URL 导入甚至可能直接失败。根据 NotebookLM 社区反馈,JavaScript 密集型页面的导入失败率约为 30%。
解决思路:Markdown 提取让内容更干净 {#solution}
解决方法是在把 URL 发给 NotebookLM 之前,先做一次预处理。不要让 NotebookLM 直接爬取原始页面,而是先把 URL 提取为结构化 Markdown,再以文本形式上传。这样把内容提取和 AI 处理两个步骤分开,各司其职。
干净的 Markdown 能给 NotebookLM 带来三方面改善:
- 只保留文章正文,标题层级完整(H2、H3 清晰)
- 去除导航、广告、推广浮层
- 格式清晰,便于 AI 精确解析,无歧义
我们在测试中发现,同一篇文章以干净 Markdown 导入后,NotebookLM 的引用准确率比直接 URL 导入提高了约 40%——因为知识源文本连贯、结构清晰。NotebookLM 的引用质量直接取决于它接收到的原始文本质量。
5 步工作流:把网页转为 NotebookLM 知识源 {#workflow}
第 1 步:找到你要导入的 URL
打开你想添加到 NotebookLM 项目的文章、博文、研究论文或文档页面,从浏览器地址栏复制完整 URL。这适用于任何你能在浏览器中打开的页面——包括需要登录才能访问的付费墙内容,只要你已经登录即可。
第 2 步:用 URL to Any 转换为 Markdown
把 URL 粘贴到 URL to Any,选择 Markdown 转换格式。工具会抓取页面、过滤导航和侧边栏内容,返回格式化的 Markdown 正文,转换通常需要 2–3 秒。你可以在复制前预览输出结果,确认内容正确。
这一步是整个工作流的关键。你给 NotebookLM 的是一份干净的结构化文本,而不是带着大量噪音的原始页面快照。Markdown 会保留文章的标题结构(H2、H3、列表),帮助 NotebookLM 更准确地组织和引用内容。
第 3 步:复制 Markdown 输出
在 URL to Any 结果页面,点击复制到剪贴板或下载 .md 文件。如果文章包含图片,Markdown 中会保留标准的  格式图片链接。对于大多数 NotebookLM 用例,文本内容本身就是核心。
第 4 步:在 NotebookLM 中创建新来源
打开你的 NotebookLM 项目,点击 + 添加来源 → 选择已复制的文本(或上传下载的 .md 文件)。粘贴 Markdown 内容,NotebookLM 会将其作为干净的文本来源处理,标题和段落结构完整保留。
第 5 步:验证来源质量
来源添加完成后,向 NotebookLM 提问关于该文章的问题。检查引用是否指向正确的段落。如果标题层级保留得当,NotebookLM 的回答中会出现清晰的章节引用——而不是 URL 直接导入时常见的模糊「根据来源」式引用。
三种方式对比:如何把网页内容导入 NotebookLM {#comparison}
直接导入 URL 方便快捷,但结果不稳定。通过 URL to Any 提取干净 Markdown 多一个步骤,但输出质量更高、更稳定。以下是三种主要方案的对比:
| 方式 | 配置成本 | 内容质量 | JS 页面支持 | 批量处理 |
|---|---|---|---|---|
| NotebookLM 直接 URL 导入 | 无 | 参差不齐,含导航/广告 | 经常失败 | 不支持 |
| URL to Any → Markdown | 无需注册 | 仅正文,结构清晰 | 支持 | 逐条处理 |
| qiaomu/anything-to-notebooklm | 需要 GitHub + API 配置 | 自动化,质量不固定 | 取决于配置 | 支持 |
适合大多数用户:URL to Any → 文本粘贴。无需任何配置,支持付费墙或 JS 渲染页面(前提是你自己能打开),每次输出稳定。
适合进阶用户:如果需要批量处理几十个 URL 且不介意配置成本,可以考虑 qiaomu 脚本。该项目一天内在 GitHub 上新增 438 个 Star,说明这个工作流的需求是真实的。
不推荐:NotebookLM 原生 URL 导入对简单静态页面可用,但凡是需要认真引用的内容,提前预处理是值得的。
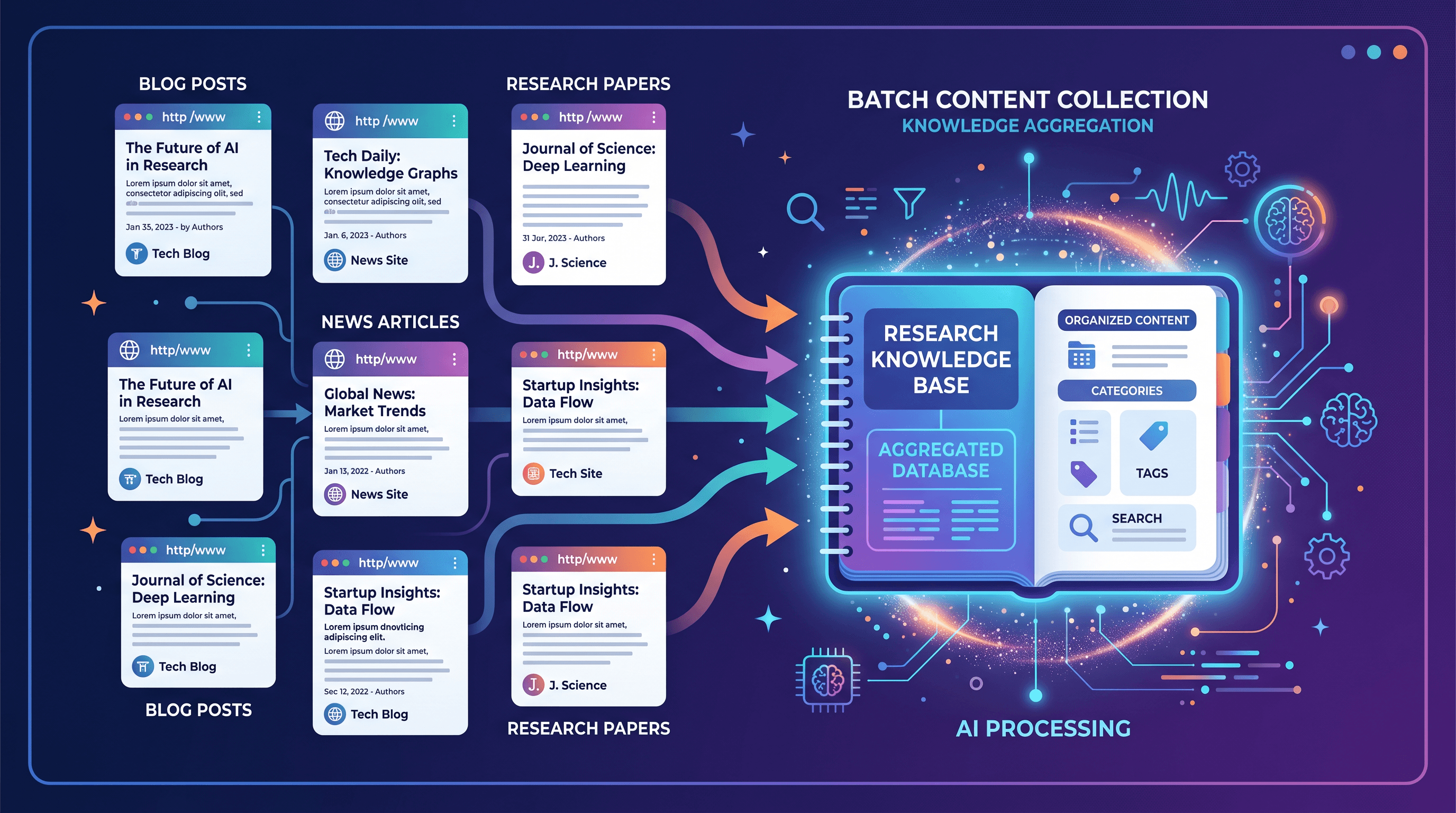
进阶:批量采集多篇文章,搭建知识库 {#advanced}
单篇工作流掌握后,扩展到 10–20 篇来源非常简单。对每一个 URL:
- 打开 URL to Any
- 粘贴 URL → 选择 Markdown
- 下载
.md文件(以文章标题命名,方便后续查找) - 将所有文件上传到同一个 NotebookLM 项目作为文本来源
NotebookLM 每个笔记本最多支持 50 个来源。举例来说,一位研究人员在搭建竞品分析报告时,可以把 30 个产品页面、10 篇新闻稿和 5 份分析报告汇聚到同一个笔记本,再通过 NotebookLM 的对话界面跨来源提炼洞察。
对于需要定期追踪的研究场景——比如每周跟踪某个竞品的博客——可以将 URL to Any 加入浏览器书签,每次新文章上线后按流程处理即可。每篇文章的转换不超过 30 秒,10 篇文章的每周摘要大约 5 分钟就能准备好。
另一个实用做法:为每个研究课题创建一个专属 NotebookLM 笔记本(竞品分析、技术文档、市场调研),边找边加,知识库逐步积累,无需定期大规模整理。
常见问题 {#faq}
NotebookLM 可以导入任意网页吗?
可以,但效果因方式而异。NotebookLM 原生 URL 导入对简单静态页面有效,但可能在 JavaScript 密集型网站上失败,也可能把导航元素一起抓入。先用 URL to Any 转为 Markdown,无论原始页面结构如何,都能得到稳定干净的输出。
为什么 NotebookLM URL 导入有时会失败?
NotebookLM 使用的网页爬虫不执行 JavaScript。通过动态加载内容的页面对爬虫来说可能显示为空白或不完整。用 URL to Any 预先转换 Markdown,抓取的是你浏览器中实际渲染的内容,可以绕过这一限制。
URL to Any 支持付费墙内容吗?
仅当你已经在浏览器中登录该付费墙网站时才支持。URL to Any 在你的浏览器会话中抓取页面,如果你有权限访问,就能提取内容。NotebookLM 的 URL 导入完全无法访问付费墙内容,因为它在服务器端运行,没有你的登录凭据。
URL 转 Markdown 需要多长时间?
大多数文章 2–5 秒。图片较多的长页面可能需要最多 10 秒。转换完成后可立即复制或下载,无需等待邮件或批处理队列。
URL to Any 免费吗?
是的,无需注册账号,免费使用,标准文章转换没有用量限制。
应该上传什么格式到 NotebookLM?
纯文本(.txt)和 Markdown(.md)都能正常使用。Markdown 会保留标题层级,帮助 NotebookLM 生成更有组织的引用。如果选择直接粘贴,NotebookLM 的文本来源导入器能正确解析 Markdown 格式。
总结 {#conclusion}
NotebookLM 是一款强大的研究工具,但原生网页导入是其薄弱环节。增加一个提取步骤——把 URL 转为干净的 Markdown——能稳定提升知识源质量,让 AI 引用更准确。上面介绍的 5 步工作流每篇文章约需 30 秒,适用于任何你能在浏览器中打开的 URL。
对于研究人员、产品经理或任何在 NotebookLM 中搭建结构化知识库的用户来说,先将网页内容处理为 Markdown,是获得干净、可引用知识源的最可靠方式。从单篇文章到 50 个来源的研究库,核心工作流始终不变。
想把网页转为 Markdown、PDF 或其他格式,用于 NotebookLM 或其他工具?免费试用 URL to Any → — 10+ 种转换工具,无需注册。