
Building URL-to-Knowledge Pipelines with Long-Context AI
Long-context AI models have crossed an important threshold: they can ingest entire reports, multi-file projects, and complex visual interfaces while coordinating tools to produce polished deliverables. That unlocks a new kind of workflow—turning a simple URL into a reliable knowledge artifact you can cite, share, and ship.
This article offers a practical, vendor-neutral framework for building URL-to-knowledge pipelines, informed by the latest advances in reasoning, vision, and tool use (e.g., models like GPT-5.2). You’ll find concrete steps, checks, and rubrics that help you move from web pages to spreadsheets, briefs, PDFs, and more—with traceability and evaluation baked in.

Table of contents
- Why long-context LLMs change URL workflows
- The URL-to-Knowledge pipeline
- Engineering best practices
- SEO and analysis tips
- Measuring quality and reliability
- FAQ
- Conclusion
Why long-context LLMs change URL workflows
Long-context and agentic capabilities make the jump from "answering questions about a page" to "producing end-to-end artifacts from many pages". Recent benchmarks show meaningful gains in:
- Long-context reasoning: near-complete recall across hundreds of thousands of tokens.
- Tool coordination: stronger multi-step reliability across complex tasks.
- Vision understanding: better layout awareness and UI/diagram interpretation.
What this means for practitioners:
- You can plan multi-source workflows (reports, contracts, transcripts) without constant manual stitching.
- You can expect cleaner formatting and fewer breakdowns across steps—though you should still double-check critical outputs.
- You can integrate visual materials (charts, dashboards, screenshots) into reasoning and deliverables.
From pages to artifacts
Think in terms of outputs you need (a formatted memo, a financial model, a slide deck), then design the pipeline backward from those artifacts. A URL is just the entry point; the real work is normalization, structure, evaluation, and traceability.
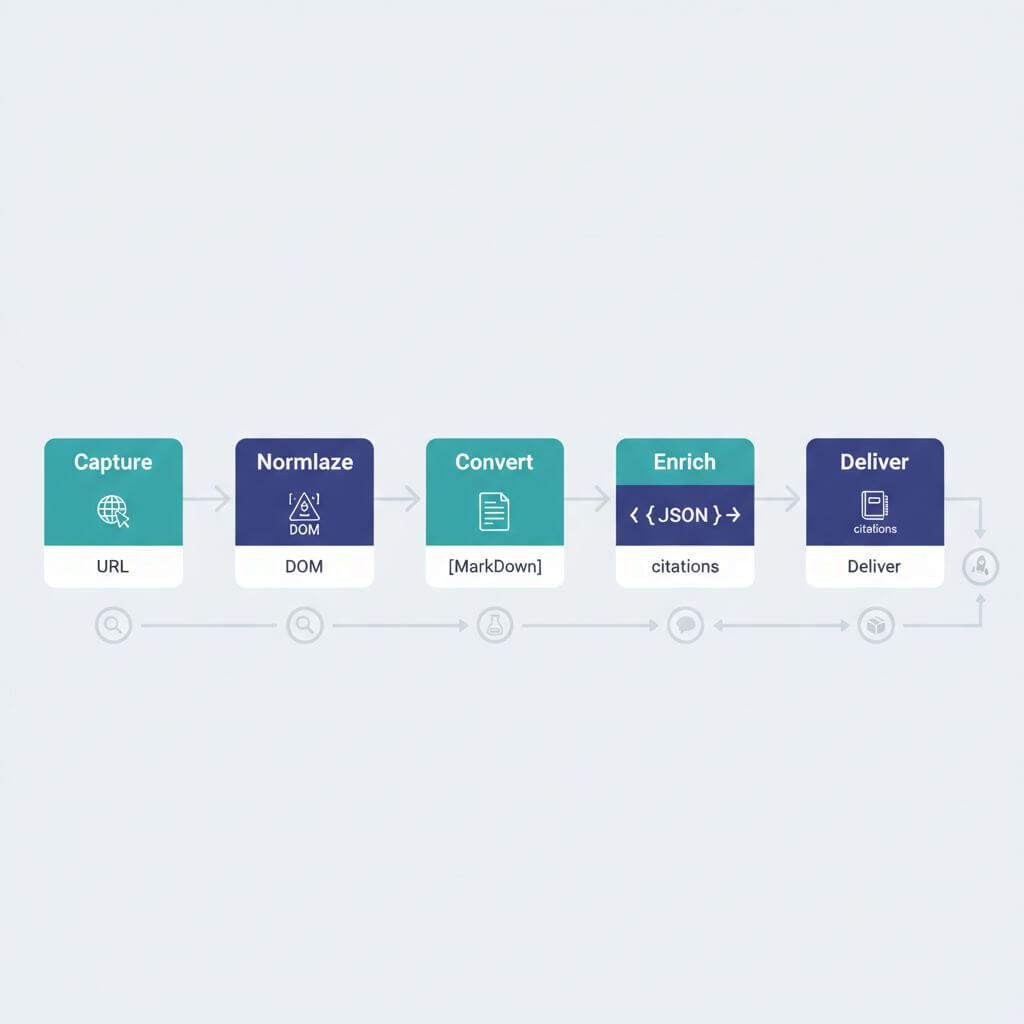
The URL-to-Knowledge pipeline
Use this six-stage blueprint to move from a URL to a trustworthy deliverable.
1) Capture and snapshot
- Resolve redirects and record the canonical URL and timestamp.
- Save a raw HTML snapshot for provenance; keep a lightweight text/Mardown version for quick inspection.
- If the page is dynamic, capture a prerendered DOM (e.g., headless browser) and note which scripts ran.
2) Normalize and clean
- Strip boilerplate (menus, ads) while preserving semantic cues: headings, lists, captions, alt text.
- Keep references: anchors, citations, footnotes, and schema.org metadata.
- Compute dedup hashes on normalized content (e.g., MD5 of text-only) to avoid reprocessing equivalent pages.
3) Convert to working formats
Different tasks benefit from different representations:
- Markdown: best for editorial workflows and human review.
- Clean HTML: preserves layout and links for fidelity.
- Plain text: compact for prompt contexts.
- JSON/XML: machine-readable for programmatic pipelines and structured ingest.
- PDF/Image: shareable artifacts and immutable snapshots.
- Audio (TTS/MP3): accessibility and podcast-style narration.
4) Enrich with metadata and structure
- Extract meta tags (title, description, canonical, Open Graph, Twitter Cards) and validate lengths.
- Parse heading hierarchy (H1–H6) to understand document structure and quality.
- Identify tables, figures, and code blocks; add labels for downstream referencing.
- Compute reading level, section summaries, and citation anchors.
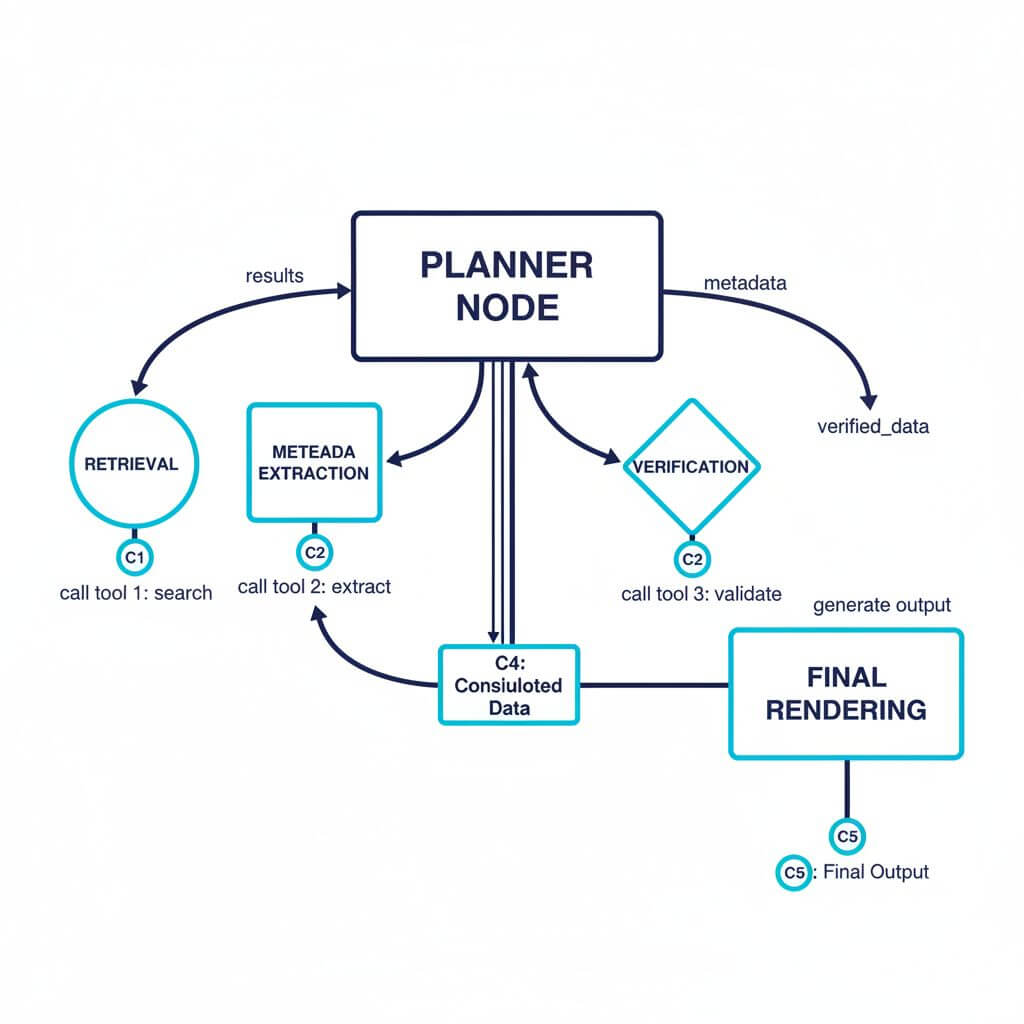
5) Reason over context
- Plan before you generate: outline sources, assumptions, and deliverables.
- Use retrieval-style orchestration even with large context windows; keep source chunks referenceable.
- For multi-step workflows, ensure tool calls are idempotent and stateful (store intermediate results with hashes).
- Add verification passes: compare final claims against source chunks; flag weak evidence.
6) Deliver with traceability
- Embed citations inline (section anchors, paragraph indices) and attach a sources appendix.
- Provide both editable and immutable formats (e.g., docx + PDF).
- Log the pipeline steps, versions, and parameters to make outputs reproducible.
Engineering best practices
Canonicalization and dedup
- Normalize URLs (http/https, trailing slashes, query params order).
- Deduplicate by content hash after normalization; optionally retain a similarity index for near-duplicates.
Chunking for long contexts
- Chunk around semantic units (sections, headings) with 1500–4000 token targets and ~10% overlap.
- Keep unique IDs per chunk and a pointer to its source URL + anchor.
- Build small, task-specific working sets instead of pushing everything into one massive prompt.
Cost, latency, and caching
- Cache converted artifacts (Markdown, clean HTML, JSON) keyed by URL + content hash.
- Use programmatic heuristics to avoid sending non-essential boilerplate.
- Prefer structured prompts and compact references; separate planning from generation.
Privacy, compliance, and robots
- Respect robots.txt and site terms; handle personal data carefully (PII scrubbing, opt-outs).
- Use short-lived storage and encryption for sensitive snapshots.
- Honor licensing; summarize rather than reproduce when necessary; cite properly.
SEO and analysis tips
Meta tags
- Validate canonical consistency; avoid conflicting OG/Twitter titles and duplicate descriptions.
- Track character counts, truncation risk, and schema.org presence.
Headings and structure
- Check for single H1 and sensible H2/H3 progression.
- Flag orphan sections, excessive depth, or overly long headings.
Share flows
- Generate QR codes for print contexts that jump to the canonical URL.
- Include shareable artifacts (PDF/image) for non-technical stakeholders.
Measuring quality and reliability
Design a rubric that aligns with your deliverable. Score each output on:
- Correctness: factual alignment with sources; clear citations.
- Completeness: coverage of scope, edge cases, and constraints.
- Formatting: layout, tables, figures, and consistent styles.
- Traceability: reproducible pipeline steps and versioning.
- Tool reliability: success rate across multi-turn calls; timeouts and retries.
Operationalize it:
- Maintain a small benchmark set of representative URLs and tasks.
- Track token usage, latency, error classes, and human corrections.
- Run periodic regressions when upgrading models or changing chunking strategies.
FAQ
- How do I choose between raw HTML and Markdown?
- Store both. HTML preserves fidelity for re-rendering; Markdown is compact for review and prompts.
- What if my documents exceed the context window?
- Chunk semantically; retrieve only relevant sections; maintain anchors for citation.
- How can I reduce hallucinations?
- Ground the model with explicit source chunks; add verification passes; prefer structured outputs.
- Should I include images in the prompt?
- Yes for charts/diagrams/UI; compress with text summaries and refer back to labeled regions.
Conclusion
Long-context, agentic LLMs make it practical to turn URLs into high-quality, traceable deliverables. The key is engineering the pipeline—capture, normalize, convert, enrich, reason, and deliver—while measuring reliability over time.
If you need quick URL conversion in the browser (Markdown, HTML, Text, JSON, XML, PDF, images, audio), consider URL to Any (https://urltoany.com) as one option to plug into your tooling stack.