
A Case Study in PDF Forensics: The Epstein PDFs
The US Department of Justice’s release of documents under the Epstein Files Transparency Act has reignited public scrutiny of redacted PDFs. This case study distills the technical findings and clarifications reported by the PDF Association, focusing strictly on file structure, syntax, and digital forensics—not on document content or legal interpretation. Our goal is to help practitioners evaluate similar disclosures without falling prey to misinformation.
Assumptions and scope: the forensic perspective here synthesizes the reference analysis with standard PDF diagnostics. Not every file was examined; product mentions do not imply endorsement; this is not legal advice.

- 26 December 2025 update
- The files we examined
- File validity
- PDF versions
- Incremental updates
- Bates numbering
- The first incremental update
- Different incremental updates
- Metadata
- Photographs
- Scanned documents – or are they?
- FAQ
- Conclusion
26 December 2025 update
The DoJ later released DataSet 8.zip (9.95 GB compressed) including 10,593 new PDFs (~1.8 GB, 29,343 pages; the longest document has 1,060 pages) plus large MP4s, spreadsheets, and other files. The first and last PDFs in the set are reported as:
- VOL00008\IMAGES\0001\EFTA00009676.pdf
- VOL00008\IMAGES\0011\EFTA00039023.pdf
A cursory scan showed pdfinfo properties broadly similar to earlier datasets; no deep analysis of DataSet 8 was reported.
Importantly, various online claims about “recoverable redactions” in the Epstein PDFs were addressed: for the EFTA PDFs in Datasets 01–07, the analysis states the redactions were correctly applied and do not contain recoverable text. A media example (VOL00004\IMAGES\0001\EFTA00005855.pdf) was cited as fully and correctly redacted. Extractable text, where present, is limited to low-quality OCR artifacts and the Bates numbers.
The files we examined
This case study focuses on a random subset of PDFs from the EFTA disclosure. The analysis prioritizes:
- Syntax and structure (objects, xref tables/streams, trailers, EOF)
- Incremental updates and their intent (stamps, redactions, OCR, assembly)
- Metadata/XMP, embedded resources, and visible/hidden content
- Idioms typical of litigation and FOIA workflows (Bates, .OPT load files)
We do not analyze the documents’ narrative content, and we avoid tool-specific judgments beyond technical behavior.
File validity
Well-formed PDFs meet ISO 32000 requirements for headers, cross-references, trailers, and EOF markers. Practical checks include:
pdfinfoto read header/version, page count, page sizeqpdf --checkorqpdf --validate=pdf20to flag structural issues- Heuristics: a single %%EOF, consistent xref, matching object counts
Common validity pitfalls that are not necessarily malicious:
- Producer quirks (non-standard metadata, extra whitespace)
- Legacy linearization leftovers
- Minor anomalies in object ordering or trailer dictionaries
PDF versions
Multiple PDF versions can appear across a corpus due to mixed toolchains and historical edits. Observations typically include:
- Older 1.x files coexisting with newer 2.0-flavored outputs
- Object streams and compressed xrefs in later versions
- Version bumps caused by specific features (e.g., transparency, XMP)
Forensic takeaway: version diversity alone is not suspicious; it often reflects routine processing by different software over time.
Incremental updates
An incremental update appends new objects and xrefs, preserving prior content. It’s common in:
- Bates stamping and page label updates
- Redaction workflows (especially if burn-in occurs in a later pass)
- OCR passes that add hidden or artifact text layers
Key indicators:
- Multiple %%EOF markers with appended xref sections
- Trailers indicating previous revisions
- Appearance changes without complete file rewrites
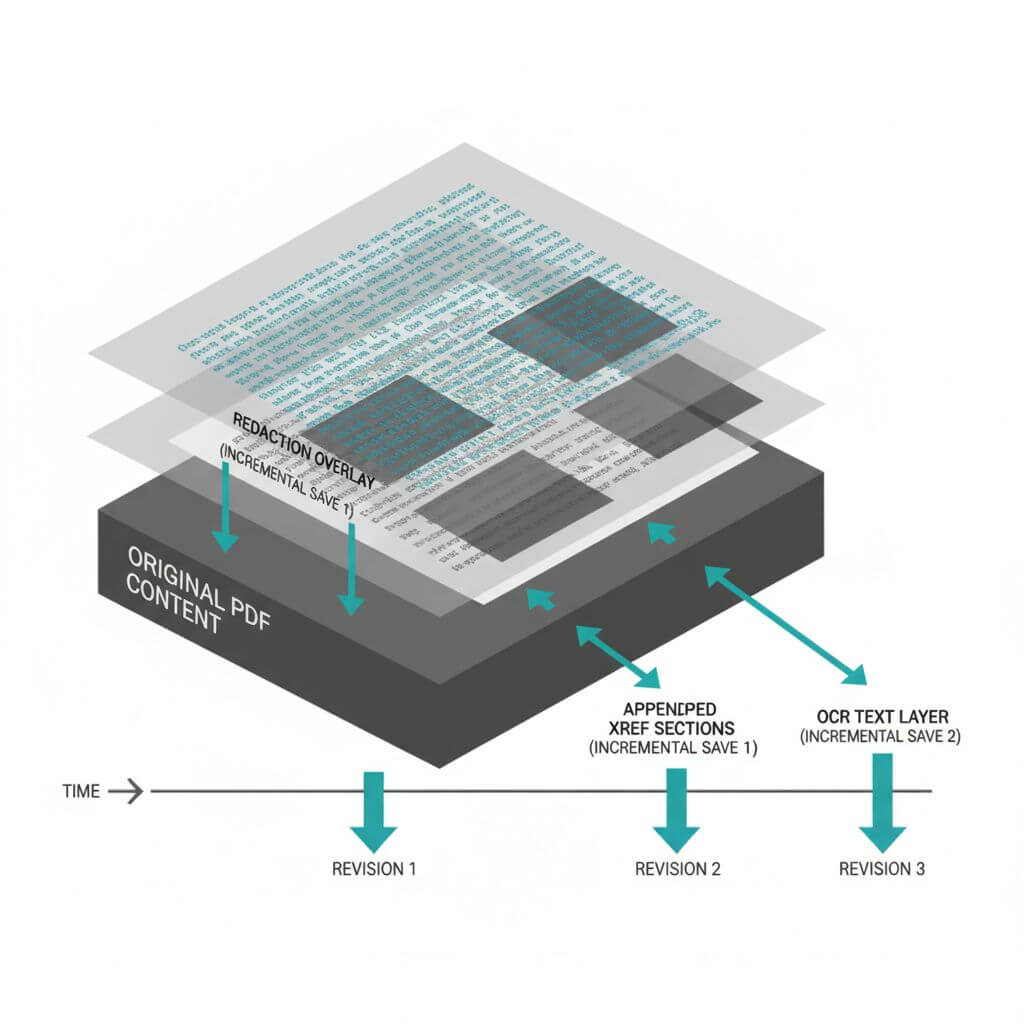
What to verify in incremental updates
- Are redactions vector/bitmap overlays or truly burned-in removals?
- Are hidden layers or annotations left intact?
- Are update steps consistent with expected workflow (e.g., stamp → redact → OCR)?
Bates numbering
Bates numbers are page-level identifiers used in litigation. In the EFTA data, references to Bates numbers and “.OPT” load files are consistent with standard eDiscovery practices.
Forensic checks:
- Confirm Bates appears as stamped content on each page
- Ensure text extraction returns Bates where expected
- Correlate filenames and page ranges with load files (.OPT) when available
Practical tip: searching load files for a Bates range can quickly locate a document of interest across large corpora.
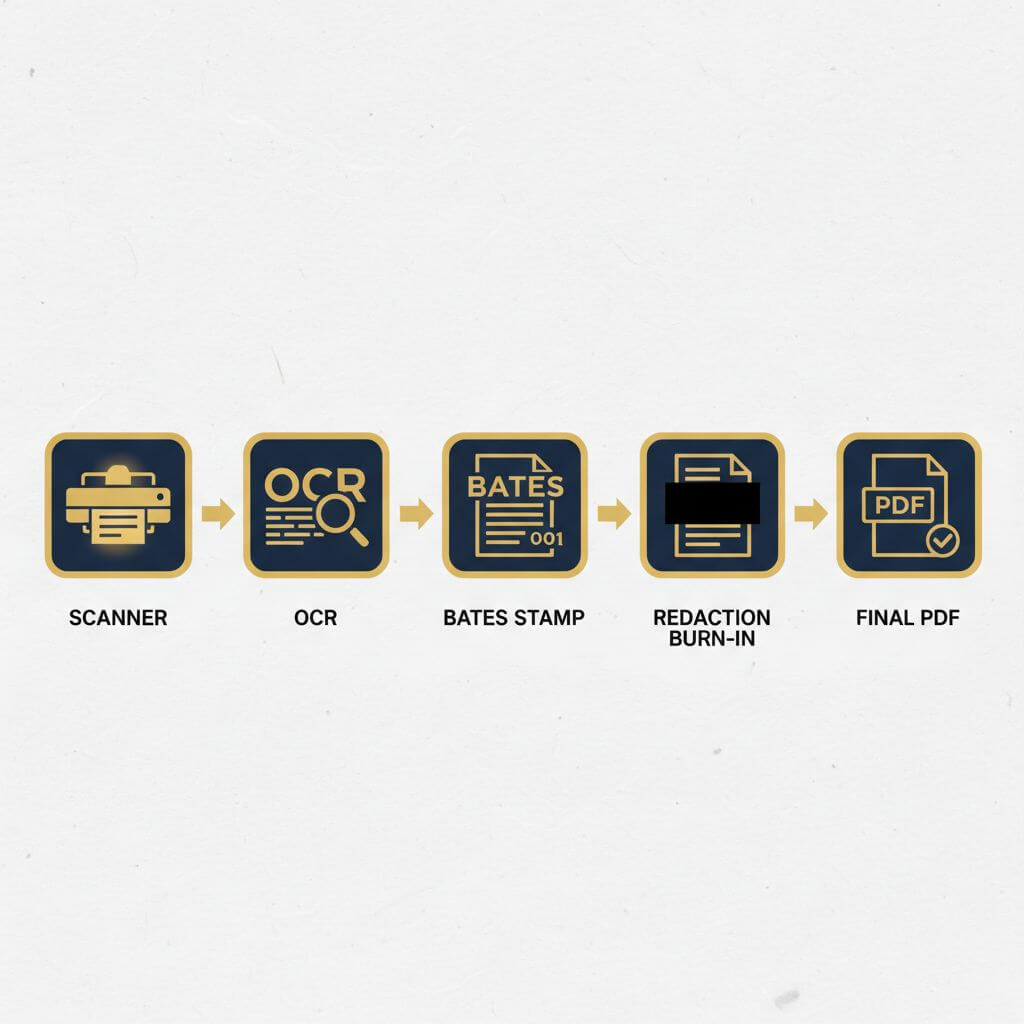
The first incremental update
The initial appended revision frequently coincides with document assembly milestones:
- Ingestion and normalization (page size, rotation)
- Applying a Bates range
- Initial OCR to enable searchability
How to inspect:
- Compare object count and xref before/after the first update
- Look for new Form XObjects or annotation dictionaries tied to stamps
- Review Producer/Creator metadata shifts that mark a workflow stage
Different incremental updates
Subsequent updates often reflect:
- Redaction passes (with burn-in) and visual masks
- Additional OCR clean-ups or language packs
- Page replacements (e.g., improved scans) or added exhibits
Differentiating update intent:
- Redaction tools may inject specific prefix/suffix object names
- OCR layers tend to add content streams with marked-content tags
- Page replacements manifest as new XObjects or page dictionaries
Metadata
Metadata comes from both Info dictionaries and XMP. Expect:
- Producer/Creator differences across tools and dates
- Mixed or missing author/title, often neutralized in legal workflows
- Limited or removed EXIF where source images are recompressed into PDFs
Verification steps:
exiftool -XMP:all -s -G file.pdffor XMP- Compare Info vs XMP; mismatches can be benign tool artifacts
- Look for redaction/sanitization markers in Producer/Creator strings
Photographs
When PDFs include photos:
- Embedded images are typically recompressed, often stripping original EXIF n- Downsampling and color-profile conversions are common
- Forensic signs include block boundaries (JPEG), ICC profiles, and image XObject reuse
Interpretation caution: recompression is routine in eDiscovery; absence of camera EXIF inside a PDF does not imply tampering.
Scanned documents – or are they?
Scanned-looking pages may still contain layered artifacts:
- OCR text artifacts (sometimes garbled) to enable selection/search
- Vector redaction rectangles that are subsequently burned-in
- Page crops/rotations that differ from physical paper sizes
To assess “scan vs synthetic”:
- Check for selectable text (
pdftotext, Ctrl+A) and examine output entropy - Inspect content streams for image-only pages versus mixed vector/text
- Validate that any redaction is not an annotation but an actual removal/burn-in
FAQ
Are the EFTA PDFs’ redactions recoverable?
According to the referenced analysis, for Datasets 01–07 the EFTA PDFs were correctly redacted and do not contain recoverable text under the black boxes. Some poor OCR artifacts and the Bates numbers may remain extractable, which is expected.
Why do malware-analysis sites sometimes flag PDFs?
Heuristics can misinterpret benign features (JavaScript entries, embedded files, or unusual object graphs). Structural anomalies or incremental updates are not, by themselves, indicators of malware or hidden text.
What quick checks should practitioners run?
pdfinfoto confirm version/pagesqpdf --checkfor structure- Text extraction to see what’s selectable
- Manual spot-inspection of suspect redactions in a hex/object browser
How do .OPT files matter?
.OPT load files map Bates numbers to image/PDF pages in eDiscovery. Searching them can locate documents and verify page ranges across large datasets.
Conclusion
From a PDF-forensics perspective, the EFTA corpus exhibits patterns typical of litigation production: consistent Bates numbering, incremental updates aligned to stamping/OCR/redaction, mixed PDF versions, and metadata variation across toolchains. The high-visibility claims about recoverable redactions were addressed in the source analysis and found not to apply to the EFTA PDFs in Datasets 01–07. As always, practitioners should validate redaction workflows, confirm burn-in, and document each revision step.
If you need to quickly convert a web page to PDF or Markdown during research, you can try URL to Any (https://urltoany.com).